
目前导航功能包只接受使用sensor_msgs/LaserScan或sensor_msgs/PointCloud消息类型发布的传感器数据。
sensor_msgs/LaserScan和 sensor_msgs/PointCloud跟其他的消息一样,包括tf帧和与时间相关的信息。字段frame_id存储与数据相关联的tf帧信息。以激光扫描为例,它将是激光数据所在帧。
我们使用laser_geometry包将雷达的scan转换为点云,它只有一个C++类LaserProjection,没有ROS API.
有两个函数可以将sensor_msgs/LaserScan转换为sensor_msgs/PointCloud或者sensor_msgs/PointCloud2。 projectLaser()简单快速,不改变数据的frame; transformLaserScanToPointCloud()速度慢但是精度高,使用tf和sensor_msgs/LaserScan的time_increment转换每束激光,对倾斜的雷达或移动的机器人,推荐这种方法。
sensor_msgs/PointCloud还包括一些额外的通道,例如intensities, distances, timestamps, index 或者thew viewpoint
支持将三维空间中的点的数组以及任何保存在一个信道中的相关数据。例如,一条带有intensity信道的 PointCloud 可以保持点云数据中每一个点的强度。
它执行最简单的激光投射,每束激光投射出去的角度根据的是以下公式: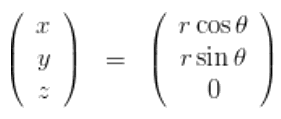
但最后形成的点云消息,坐标系还是laser,不适用于雷达移动或畸变不能忽略的情况。
这种方法需要tf变换,由于我们是扫描过程中一直收集数据,选择的target_frame必须是固定的。因为sensor_msgs/LaserScan的时间戳是第一次测量的时间,这个时间还无法转换到target_frame,得等到最后一个雷达的测量时间完成坐标系转换。
依赖包是laser_geometry, pcl_conversions, pcl_ros
修改package.xml文件,添加1
2<build_depend>libpcl-all-dev</build_depend>
<exec_depend>libpcl-all</exec_depend>
1 |
|
参考:
激光LeGO-LOAM生成pcd点云地图保存和格式转换
LaserScan转pcl::PointCloud
laser_geometry
PCL包括多个子模块库。最重要的PCL模块库有如下:过滤器Filters、特征Features、关键点Keypoints、配准Registration、Kd树Kd-tree、八叉树Octree、切分Segmentation、Sample Consensus、Surface、Range Image、文件读写I/O、Visualization、通用库Common、Search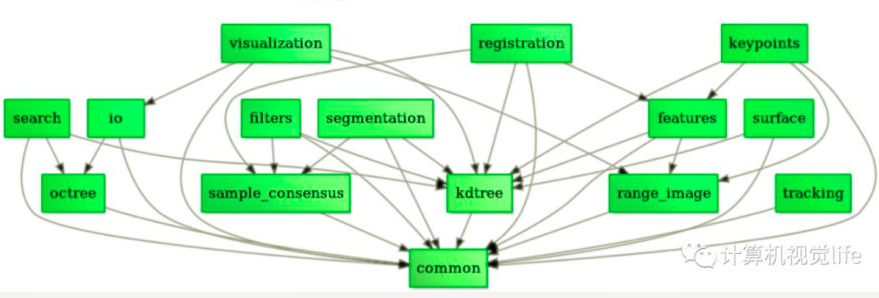
PCL中的所有模块和算法都是通过Boost共享指针来传送数据的,因而避免了多次复制系统中已存在的数据的需要
ROS中已经安装了pcl,不必再安装了,而且网上给的那个源一直添加失败,服务器在国外。但是ROS的pcl缺工具包,比如查看点云图片的pcl_viewer。它的安装命令是:sudo apt-get install pcl-tools
优点:
可以表达物体的空间轮廓和具体位置
点云本身和视角无关,也就是你可以任意旋转,可以从不同角度和方向观察一个点云,而且不同的点云只要在同一个坐标系下就可以直接融合
缺点:
点云并不是稠密的表达,一般比较稀疏,放大了看,会看到一个个孤立的点。它的周围是黑的,也就是没有信息。所以在空间很多位置其实没有点云,这部分的信息是缺失的。
点云的分辨率和离相机的距离有关。离近了看不清是个什么东西,只能拉的很远才能看个大概。
编译pcl-1.81
2
3
4
5
6mkdir build
cd build
# 配置cmake
cmake -DCMAKE_BUILD_TYPE=None -DCMAKE_INSTALL_PREFIX=/usr \ -DBUILD_GPU=ON-DBUILD_apps=ON -DBUILD_examples=ON \ -DCMAKE_INSTALL_PREFIX=/usr ..
make
sudo make install
如果ubuntu 22.04且通过sudo apt install libpcl-dev安装的pcl。那么pcl版本可能是1.12,如果vtk版本正好又是9.1,二者存在冲突会导致不能正常显示。
1 | cmake_minimum_required(VERSION 2.6) |
PointXYZ是使用最常见的一个点数据类型,因为他之包含三维XYZ坐标信息,这三个浮点数附加一个浮点数来满足存储对齐,可以通过points[i].data[0]或者points[i].x访问点X的坐标值1
2
3
4
5
6
7
8
9
10union
{
float data[4];
struct
{
float x;
float y;
float z;
};
};
PointXYZRGB也是个union,成员如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15union{
float data[4];
struct
{
float x;
float y;
float z;
};
};
union{
struct{
float rgb;
};
float data_c[4];
};
在使用PCL库的时候,经常需要显示点云,可以用下面这段代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
typedef pcl::PointXYZRGB PointT;
typedef pcl::PointCloud<PointT> PointCloudT;
PointCloudT::Ptr cloud(new PointCloudT);
cloud->is_dense = false;
// 打开点云文件,获取的是vertex
if(pcl::io::loadPLYFile("file.ply", *cloud) <0 )
{
PCL_ERROR("loading cloud failed !");
return -1;
}
cout<< "点云共有: "<< cloud->size()<<"个点"<<endl; //文件中vertex的个数
pcl::visualization::CloudViewer viewer ("Viewer");
viewer.showCloud(cloud);
while (!viewer.wasStopped ())
{
}
1 | pcl::transformPointCloud (*cloud_in, *cloud_out, matrix); |
cloud_in为源点云,cloud_out为变换后的点云,注意这里的matrix是4X4的欧拉矩阵,也就是第一行为R,t;第二行为0,1的矩阵
对于CloudViewer类来说,其方法有大致以下几类1
2
3
4
5
6
7
8
9
10
11
12void showCloud()
void wasStopped() // 关闭窗口
void runOnVisualizationThread()
void runOnVisualizationThreadOnce ()
void removeVisualizationCallable()
// 键盘鼠标的响应
boost::signals2::connection registerKeyboardCallback()
boost::signals2::connection registerMouseCallback()
boost::signals2::connection registerPointPickingCallback()
常用代码:1
2
3
4
5
6pcl::visualization::CloudViewer viewer("3D Point Cloud Viewer");
// 除了显示什么都不能干
viewer.showCloud(m_cloud);
while(!viewer.wasStopped())
{
}
如果只是简单显示点云,调用CloudViewer就可以了。PCLVisualizer更加强大,可以改变窗口背景,还可以添加球体,设置文本,功能特别丰富1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18boost::shared_ptr<pcl::visualization::PCLVisualizer> viewer(new pcl::visualization::PCLVisualizer("3D Viewer"));
viewer->setBackgroundColor(0, 0, 0);
int v1(0);
int v1(1);
// 视窗的x轴最小值,y轴最小值,x轴最大值,y轴最大值
viewer->createViewPort(0.0, 0, 0.5, 1.0, v1); //创建左视窗
viewer->createViewPort(0.5, 0, 1.0, 1.0, v2); //创建右视窗
viewer->addPointCloud<pcl::PointXYZ>(cloud, "sample cloud");
viewer->setPointCloudRenderingProperties(pcl::visualization::PCL_VISUALIZER_POINT_SIZE, 1, "sample cloud");
viewer->addCoordinateSystem(1.0);
viewer->initCameraParameters();
// 代码最后,都会出现这样一个while循环,在spinOnce中为界面刷新保留了时间
while (!viewer->wasStopped())
{
viewer->spinOnce(100); // 多长时间调用内部渲染一次
boost::this_thread::sleep(boost::posix_time::microseconds(100000)); //延时0.1秒
}
addPointCloud函数将点云添加到视窗对象中,并定义一个唯一的字符串作为ID号,利用此字符串保证在其他成员方法中也能标识引用该点云,多次调用addPointCloud(),可以实现多个点云的添加,每调用一次就创建一个新的ID号。如果想更新一个已经显示的点云,可以使用updatePointCloud函数。删除有removePointCloud(ID号)和removeAllPointClouds。 这里使用的是最简单的一个重载,此外可以在第二个参数添加PointCloudColorHandler或PointCloudColorHandler
1 | bool next_iteration = false; |
1 | // 初始化相机参数 |
还可以对不同的视窗添加文字和背景颜色
launch修改如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20<launch>
<param name="/use_sim_time" value="false" />
<param name="robot_description"
textfile="$(find cartographer_ros)/urdf/backpack_2d.urdf" />
<node name="robot_state_publisher" pkg="robot_state_publisher"
type="robot_state_publisher" />
<node name="cartographer_node" pkg="cartographer_ros"
type="cartographer_node" args="
-configuration_directory $(find cartographer_ros)/configuration_files
-configuration_basename backpack_2d.lua"
output="screen">
<remap from="echoes" to="horizontal_laser_2d" />
</node>
<node name="cartographer_occupancy_grid_node" pkg="cartographer_ros"
type="cartographer_occupancy_grid_node" args="-resolution 0.05" />
</launch>
一个终端先运行launch,再到另一个终端运行rosparam set use_sim_time true,再播放cartographer_paper_deutsches_museum.bag,否则会有时间戳问题
如果只运行bag文件是没有tf信息的,其实是在urdf里面: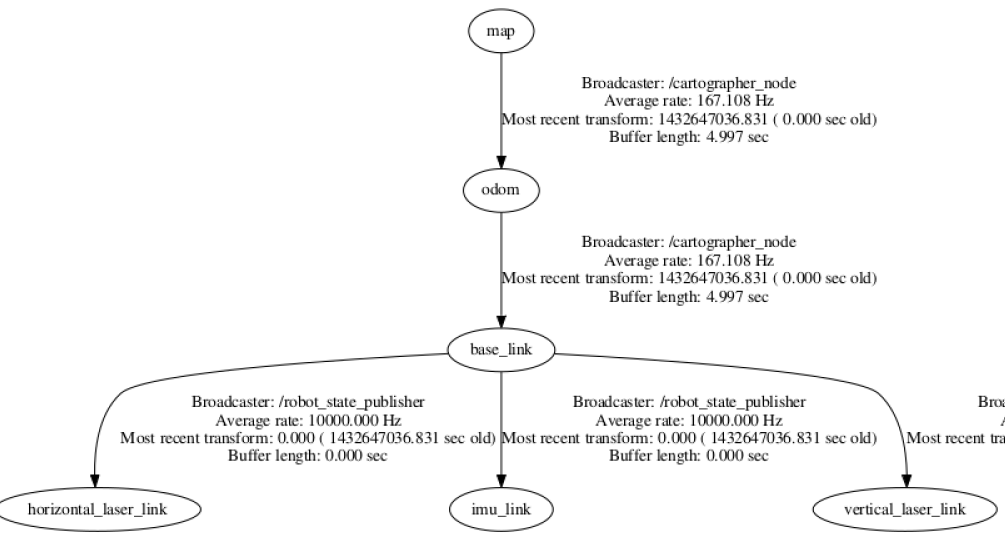
使用rosbag最好不要加倍播放,很可能出现tf的时间戳问题,可能是lookup时间导致 
注意rviz需要有这三项
我的rviz插件的名称和官方不同,保证话题一样就行:
我先拿思岚A2雷达测试,运行雷达的命令是:roslaunch rplidar_ros rplidar.launch,参见ROS中使用激光雷达(RPLIDAR)
复制/catkin_ws/src/cartographer_ros/cartographer_ros/configuration_files/revo_lds_.lua文件为no_odom_and_imu.lua,在它基础上修改22和23行:1
2tracking_frame = "base_footprint", --原来是laser
published_frame = "base_footprint", --原来是laser
复制catkin_ws/src/cartographer_ros/cartographer_ros/launch/demo_revo_lds.launch为home_map_no_odom.launch,在它基础上修改23行: -configuration_basename no_odom_and_imu.lua",最终是这样:1
2
3
4
5
6
7
8
9
10<launch>
<node name="cartographer_node" pkg="cartographer_ros"
type="cartographer_node" args="
-configuration_directory $(find cartographer_ros)/configuration_files
-configuration_basename no_odom_and_imu.lua"
output="screen">
</node>
<node name="cartographer_occupancy_grid_node" pkg="cartographer_ros"
type="cartographer_occupancy_grid_node" args="-resolution 0.05" />
</launch>
现在跟普通的launch文件不一样了,我们需要的是/home/user/catkin_ws/install_isolated/share/cartographer_ros中的launch和lua,此时还没有,可以直接复制过去或者重新编译:1
2cd ~/catkin_ws
catkin_make_isolated --install --use-ninja
添加source install_isolated/setup.zsh到 bash.rc,否则执行 roslaunch 会找不到文件。
现在运行roslaunch cartographer_ros home_map_no_odom.launch,效果如下: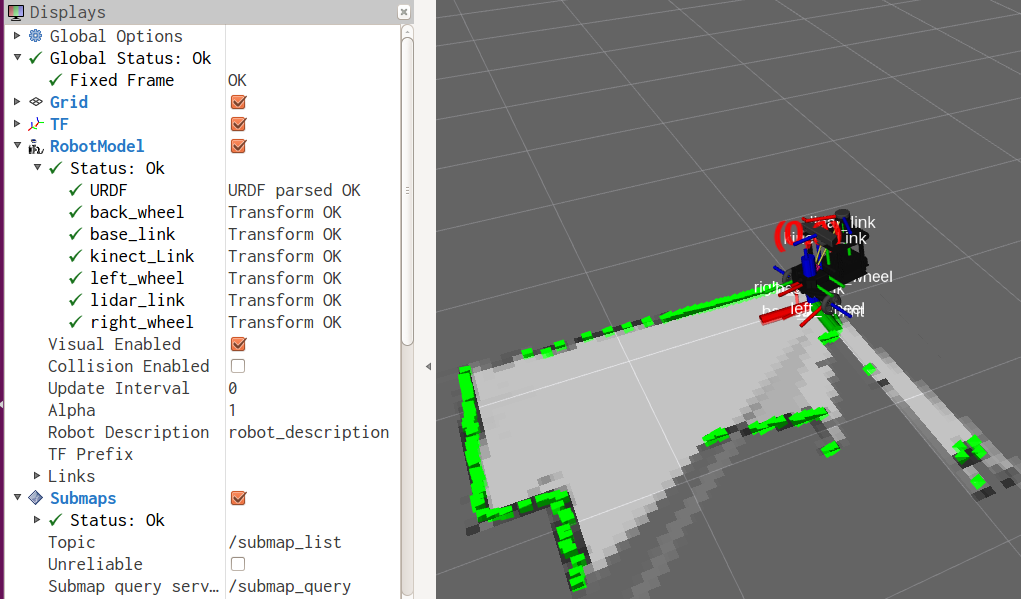
启动后,不移动时,正常的建图日志1
2
3
4
5
6
7
8
9
10
11
12Extrapolator is still initializing.
[pose_graph_2d.cc:148] Inserted submap (0, 0).
[pose_graph_2d.cc:538] Remaining work items in queue: 0
[constraint_builder_2d.cc:284] 0 computations resulted in 0 additional constraints.
[constraint_builder_2d.cc:286] Score histogram: Count: 0
[motion_filter.cc:42] Motion filter reduced the number of nodes to 4.2%.
[pose_graph_2d.cc:538] Remaining work items in queue: 0
[constraint_builder_2d.cc:284] 0 computations resulted in 0 additional constraints.
[constraint_builder_2d.cc:286] Score histogram: Count: 0
scan rate: 13.27 Hz 7.54e-02 s +/- 2.37e-03 s (pulsed at 100.01% real time)

cartographer_node是各个节点或话题的枢纽。它订阅话题scan,有时会有imu(惯导数据),然后完成定位与子图的构建,并发布话题 submap_list。 submap_list这个话题被/cartographer_occupancy_grid_node订阅,用于构建子图占用的栅格地图。
首先不再接受进一步数据1
rosservice call /finish_trajectory 0
rviz的建图画面会冻结,service的response如下:1
2
3status:
code: 0
message: "Finished trajectory 0."
日志如下:1
2
3
4
5Shutdown the subscriber of [scan]
[ map_builder_bridge.cc:152] Finishing trajectory with ID '0'...
[pose_graph_2d.cc:538] Remaining work items in queue: 0
[constraint_builder_2d.cc:284] 0 computations resulted in 0 additional constraints.
[constraint_builder_2d.cc:286] Score histogram: Count: 0
这是结束轨迹,进行最终优化
然后序列化保存其当前状态:1
rosservice call /write_state "{filename: '${MAPS}/home.pbstream'}"
pbstream文件是个二进制文件,包含已经保存的SLAM状态,可以在启动cartographer_node时加载
再将pbstream 转换为pgm和yaml1
rosrun cartographer_ros cartographer_pbstream_to_ros_map -map_filestem=${MAPS}/home -pbstream_filename=${MAPS}/home.pbstream -resolution=0.05
然后出现:1
2[pbstream_to_ros_map_main.cc:50] Loading submap slices from serialized data.
[pbstream_to_ros_map_main.cc:70] Generating combined map image from submap slices.
生成pgm和yaml文件
其实可以不结束轨迹直接保存地图
正式使用时,我在机器人工控机装好了 cartographer,在本地通过SSH启动,结果出现了报错:submapslist话题的md5值不同
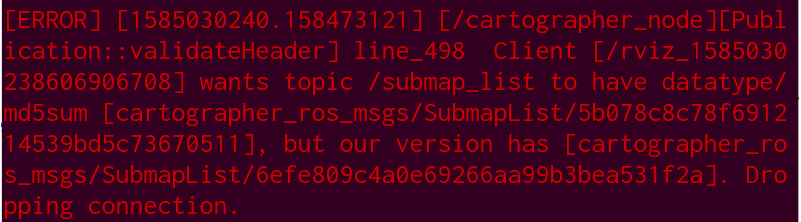
建出来的图是这样的:
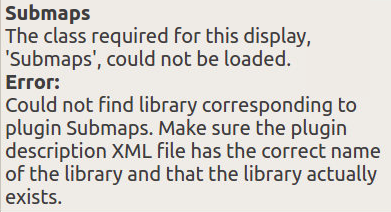
这是因为本机的rviz缺了一个插件,在编译carto时会装到rviz上,这就是一个棘手的问题,如果要在本机上开启rviz,就要在本机也把cartographer这一套编译通过,也就是需要装两次。如果本机安装不成功,还可以使用vncserver在远程机上启动rviz

参考:
安装过程
参数 /robot_pose 的设置
1 | ros::NodeHandle nh; |
/move_base/controller_frequency的设置1
2
3
4// 在 move_base 节点内
ros::NodeHandle n("~/");
double control_frequency;
n.param("controller_frequency", control_frequency, 15.0);
参数 /move_base/Planner/linear_vel 的设置1
2
3// 在 move_base 节点内
ros::NodeHandle nh("~/" + string("Planner") );
nh.param("linear_vel", linear_vel_, 0.3);
1 | ros::init(argc, argv, "my_node_name"); |
平时对nh,是用无参的构造函数,此时对应的话题是topic1。 加上~后,sub1订阅的话题是my_node_name/topic1。如果不是~,而是word,话题是/word/topic1
对于sub2,命名空间是~foo,相当于上面两种的组合,订阅的话题是my_node_name/foo/topic2
当然可以在launch文件修改命名空间的第一级,也就是 <node pkg="package", name="my_node", type="my_bin" />
ROS的工作空间用的时间一长,就会创建很多package,有些package的编译又用到了其他的package,这时单纯使用catkin_make就会出现问题。比如package A用到了B,B里又用到了C。以往使用catkin_make --pkg编译,但是可能会需要把所有的package都处理一遍,此时处理到A时就会报错,也就无法编译B和C。比较笨的方法就是在A的CMakeLists里先把B和C注释掉,同样在B的CMakeLists里把A注释掉,先用catkin_make --pkg C编译C,再依次编译B和A。
经过研究发现使用add_dependencies就可以解决这个问题,但是不能解决find_package的问题
在A的CMakeLists里这样写:1
2
3
4
5find_package(catkin REQUIRED COMPONENTS B C)
add_executable(A_program src/A_program.cpp)
add_dependencies(A_program B C ) # B C是package名称,不是编译结果的名称
target_link_libraries(A_program ${catkin_LIBRARIES} B_program C_program)add_dependencies必须在add_executable之后,可以在target_link_libraries之前或之后。 这样在编译A的时候,会出现一句scanning dependencies,这时编译器就会注意到A的依赖项,等依赖项完成后再编译A。同样在B的CMakeLists里添加C作为依赖项。
有些package需要依赖自定义的消息或服务文件,也就是一个特殊的package,这就更简单了,有专门的命令: add_dependencies(your_program ${catkin_EXPORTED_TARGETS}),不必用专门的package名称,用message函数可以看这个宏的内容,它是一大堆消息和服务名称。这样在编译的时候会出现这样的信息: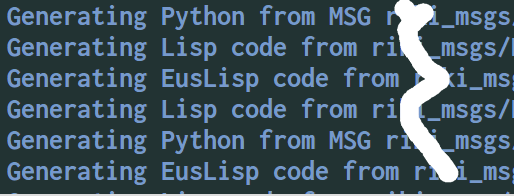
现在编译就快捷多了,直接用catkin_make就可以编译整个工作空间,不必自己改编译顺序了。
三个函数唤醒了planThread线程: MoveBase::wakePlanner MoveBase::executeCb MoveBase::executeCycle
1 | ros::NodeHandle n; |
前面就是定义一些变量和unique_lock,然后进入一个大while循环,嵌套一个while循环,由于runPlanner_在构造函数里声明为false,所以条件为真,直接锁住了这个线程,wait_for_wake仍为false
在move_base还未完全启动时,线程planThread就开始运行了,然后才会从地图数据加载代价地图。所以在启动时,不要在线程里访问一些未初始化的变量。
线程一直运行在while循环1
2
3while(wait_for_wake || !runPlanner_ )
{
}
我在move_base里定义了一个发布者pub,如果在这个while循环里执行pub.publish(msg),move_base就会出错退出。可以使用智能指针,其实Publisher该有个函数,比如isValid来验证是否可用。我发现用getTopic()函数也可以,如果结果不是空,说明发布者和roscore的通信成功了,此时可以调用publish函数了。
在上面的三个函数唤醒线程后,就往下运行,获得临时目标点,clear planner后,进入makePlan
1 | if(gotPlan) |
最后的部分就是根据全局路径规划频率,调用makePlan的地方。
先来看move_base_node.cpp的源码,我们实际需要的程序是这个:1
2
3
4
5
6
7
8ros::init(argc, argv, "move_base_node");
ros::console::set_logger_level(ROSCONSOLE_DEFAULT_NAME,ros::console::levels::Debug);
tf::TransformListener tf(ros::Duration(10));
move_base::MoveBase move_base( tf );
ros::spin();
return(0);
MoveBase构造函数开始对一些成员进行了列表初始化,没有值得说明的
1 | // 枚举变量RecoveryTrigger,可取值有PLANNING_R, CONTROLLING_R, OSCILLATION_R |
1 | //建立planner线程 |
先是运行了一个线程planner_thread_,详细看MoveBase::planThread()。接下来一共涉及了4个ros::NodeHandle对象,注册了3个话题,订阅了话题goal,订阅话题的回调函数是MoveBase::goalCB
1 | // /机器人几何尺寸有关参数 we'll assume the radius of the robot to be consistent with what's specified for the costmaps |
planner_costmap_ros_ 用于全局导航的地图controller_costmap_ros_ 用于局部导航的地图
GlobalPlanner类,继承nav_core::BaseGlobalPlanner, Provides a ROS wrapper for the global_planner planner which runs a fast, interpolated navigation function on a costmap.
1 | // 载入recovery behavior, 这部分是状态机的设计问题,优先加载用户的设置,如果没有则加载默认设置 |
每次有新的goal到来都会执行此回调函数, 如果有新目标到来而被抢占则唤醒planThread线程, 否则为取消目标并挂起处理线程
local planner的核心工作函数, 只在MoveBase::executeCb中调用一次,它是局部路径规划的工作函数,其中会调用computeVelocityCommands来规划出当前机器人的速度
1 | private_nh.param("base_local_planner", local_planner, std::string("base_local_planner/TrajectoryPlannerROS")); |
根据附近的障碍物进行躲避路线规划,只处理局部代价地图中的数据. 是利用base_local_planner包实现的。该包使用Trajectory Rollout和Dynamic Window approaches算法计算机器人每个周期内应该行驶的速度和角度。
对于全向机器人来说,也就是存在x方向的速度,y方向的速度,和角速度。DWAlocalplanner确实效率高一点。但是如果是非全向机器人,比如说只存在角速度和线速度,trajectorylocalplanner会更适用一点。
base_local_planner这个包通过地图数据,通过算法搜索到达目标的多条路经,利用一些评价标准(是否会撞击障碍物,所需要的时间等等)选取最优的路径,并且计算所需要的实时速度和角度。
其中,Trajectory Rollout 和Dynamic Window approaches算法的主要思路如下:
发送导航目标点后,首先在rviz上出现一个绿色全局路径,机器人开始行走,同时还有一个蓝色的本地路径,只是很小,不容易观察到,示意图如下: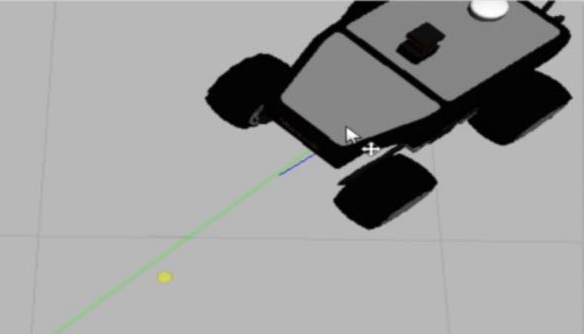
现在机器人正在按照规划的全局路径行走,地图中突然增加了一个障碍物,它不会进入全局代价地图,但会在局部代价地图中创建.所以全局路径开始没有改变,当它快接近障碍物时,局部路径检测到了它,进而会重新规划一个全局路径,这样避开了障碍物. 局部规划器把全局路径分成几部分,再执行每一部分,生成控制命令。
机器人行走时,在rviz上显示全局路径的相关话题是/move_base/DWAPlannerROS/global_plan,属于Global Map。局部规划器把全局路径的一部分发布到这个话题,代码是在DWAPlannerROS::computeVelocityCommands——DWAPlannerROS::publishGlobalPlan
rviz中显示局部路径的相关话题是/move_base/DWAPlannerROS/local_plan,属于Local Map。一旦局部路径计算出来,它就会发布到这个话题,代码是在DWAPlannerROS::computeVelocityCommands——DWAPlannerROS::publishLocalPlan
ROS的局部规划器的接口plugin类为nav_core::BaseLocalPlanner,常用的包有4种:
1 | sed -i '/committed/d' your_file` |
删除包含committed的行
1 | sed '4d' input.txt > output.txt |
实际上没有修改input.txt,而是修改文件流,然后生成到文件output.txt。前后两个文件名称不能相同,否则不能保存
aaa替换为bbb1 | sed -i "s/aaa/bbb/g" `grep aaa -rl . --include="*.cpp" ` |
grep:
--include="*.cpp" 表示仅查找cpp文件整个grep命令用`号括起来,表示结果是一系列文件名
sed -i后面是要处理的文件,s/aaa/bbb/g跟vim下的替换命令一样,表示把aaa全替换为bbb,加g表示一行有多个aaa时,要全部替换,
删除空白行: sed ‘/^$/d’ -i delete.txt
ros开头字符串的所有行1 | sed -i '/ros/d' `grep -rl "^ros" . --include="*.txt" ` |
1 | sed 's/.\{5\}//' test.log > a.log |