对于residual[1] = T(0.0);的情况,如果不加T,编译就会报错 error: no match for ‘operator=’ (operand types are ‘ceres::Jet’ and ‘double’) . Jet类型是ceres内置类型,我们要把double转成Jet类型,也就是T(0.0)
[ERROR] [1648276979.504876032]: BUG: Got a transition to CommState [PENDING] when our in SimpleGoalState [DONE] [ERROR] [1648276979.504963821]: BUG: Got a transition to CommState [RECALLING] when our in SimpleGoalState [DONE] [ERROR] [1648276979.514087412]: BUG: Got a transition to CommState [PREEMPTING] when in SimpleGoalState [DONE] [ERROR] [1648276979.515084871]: BUG: Got a second transition to DONE
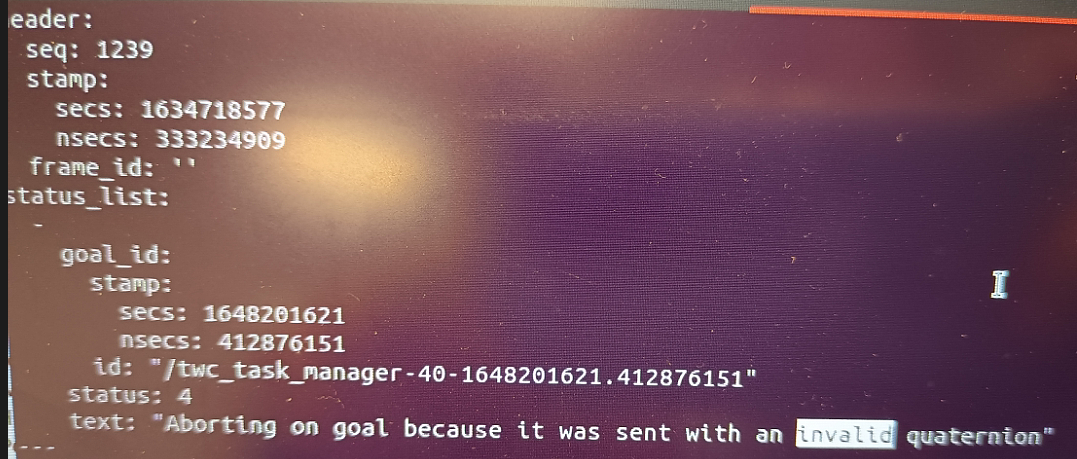
结果导致move_base漏接了一个目标,最后取消两个cancelAllGoals就好了
cancelAllGoals()[inline]: Cancel all goals currently running on the action server. This preempts all goals running on the action server at the point that this message is serviced by the ActionServer.
cancelGoal()[inline]: Cancel the goal that we are currently pursuing
PoseSequence posevec; //!< Internal container storing the sequence of optimzable pose vertices
TimeDiffSequence timediffvec; //!< Internal container storing the sequence of optimzable timediff vertices
VertexPose 继承g2o::BaseVertex<3, PoseSE2 >。 This class stores and wraps a SE2 pose (position and orientation) into a vertex that can be optimized via g2o
VertexTimeDiff继承g2o::BaseVertex<1, double>。This class stores and wraps a time difference \f$ \Delta T \f$ into a vertex that can be optimized via g2o
cyp@cyp:~$ python Python 3.6.7 (default, Oct 22 2018, 11:32:17) [GCC 8.2.0] on linux Type "help", "copyright", "credits" or "license"for more information. >>> import cv2 as cv >>> cv.__version__ '4.1.0'
# Provide the include directories to the caller set(OpenCV_INCLUDE_DIRS "/home/ubuntu/src/opencv-3.1.0/build""/home/ubuntu/src/opencv-3.1.0/include""/home/ubuntu/src/opencv-3.1.0/include/opencv")