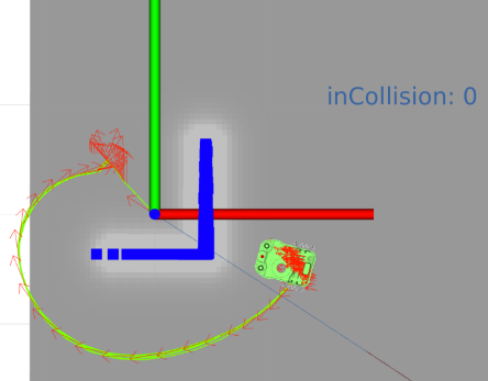
move_base/status话题堪称调试利器,有必要专门分析一下。尤其goal_id中的id可以表示move_base的客户端是什么,status和text表示导航状态
同类的move_base/result只能在导航最终结束时,发布一个消息,成功或失败,使用价值不大,不分析了。 另一个move_base/feedback和status类似,但text部分不能表现导航的最终状态。
move_base/status话题不在常用的move_base源码里,而是在actionlib的服务端代码action_server_imp.h的ActionServer<ActionSpec>::initialize()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33status_pub_ =
node_.advertise<actionlib_msgs::GoalStatusArray>("status",
static_cast<uint32_t>(pub_queue_size), true);
// read the frequency with which to publish status from the parameter server
// if not specified locally explicitly, use search param to find actionlib_status_frequency
double status_frequency, status_list_timeout;
if (!node_.getParam("status_frequency", status_frequency) )
{
std::string status_frequency_param_name;
if (!node_.searchParam("actionlib_status_frequency", status_frequency_param_name) )
{
status_frequency = 5.0;
}
else
{
node_.param(status_frequency_param_name, status_frequency, 5.0);
}
}
else
{
ROS_WARN_NAMED("actionlib",
"You're using the deprecated status_frequency parameter, please switch to actionlib_status_frequency.");
}
node_.param("status_list_timeout", status_list_timeout, 5.0);
this->status_list_timeout_ = ros::Duration(status_list_timeout);
if (status_frequency > 0)
{
status_timer_ = node_.createTimer(ros::Duration(1.0 / status_frequency),
boost::bind(&ActionServer::publishStatus, this, boost::placeholders::_1));
}
看来是通过ros的Timer轮转地发布信息。
话题的默认频率是5hz,如果要修改,可以添加move_base的参数actionlib_status_frequency,因为代码里没有默认设置这个参数 比如actionlib_status_frequency: 10
问题 1
导航时观察move_base/status,发现如下结果1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23header:
seq: 82
stamp:
secs: 379
nsecs: 572000000
frame_id: ''
status_list:
-
goal_id:
stamp:
secs: 376
nsecs: 346000000
id: "Rviz383"
status: 1
text: "This goal has been accepted by the simple action server"
---
header:
seq: 0
stamp:
secs: 381
nsecs: 731000000
frame_id: ''
status_list: []
从Rviz发目标点,突然消息全重置了(除了时间戳),连seq也为0了,原因只有一个: move_base重启了,显然是出错了。
问题 2
查看move_base/status话题,发现这样一段1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32header:
seq: 88
stamp:
secs: 1709519925
nsecs: 385386549
frame_id: " "
status_list:
goal_id:
stamp:
secs: 1709519919
nsecs: 87035653
id: "/task_dispatcher-1-1709519919.87035653"
status: 6
text: "This goal has been accepted by the simple action server"
header:
seq: 89
stamp:
secs: 1709519925
nsecs: 408925409
frame_id:
status_list:
goal_id:
stamp:
secs: 1709519919
nsecs: 87035653
id: "/task_dispatcher-1-1709519919.87035653"
status: 2
text:
...... // 重复 status: 2 的消息
这段表示,seq: 88时 task_dispatcher节点发了goal,进入导航状态,当seq: 89时,同一个节点取消了goal,也就是调用了cancelGoal函数,因为status: 2