find_package find_package用于加载第三方库,可以将需要的部分指定为组件,例如1 2 3 4 5 6 7 8 set (PACKAGE_DEPENDENCIES cartographer_ros_msgs eigen_conversions geometry_msgs urdf visualization_msgs ) find_package(catkin REQUIRED COMPONENTS ${PACKAGE_DEPENDENCIES})
REQUIRED可选字段:表示一定要找到包,找不到的话就立即停掉整个cmake。而如果不指定REQUIRED则cmake会继续执行。COMPONENTS: 可选字段,表示查找的包中必须要找到的组件,如果有任何一个找不到就算失败,类似于REQUIRED,导致cmake停止执行。
使用Find_Package寻找模块时,每一个模块都会产生如下变量:1 2 3 _FOUND _INCLUDE_DIR _LIBRARY or _LIBRARIES
INCLUDE_DIRECTORIES中,_LIBRARY加入到TARGET_LINK_LIBRARIES中
module 模式 find_package将先到module路径下查找 Find<name>.cmake。首先它搜索 ${CMAKE_MODULE_PATH}中的所有路径,然后搜索 /usr/share/cmake-3.5/Modules.比如find_package(Boost)搜索的文件是/usr/share/cmake-3.5/Modules/FindBoost.cmake
如果在CMakeLists.txt中没有下面的指令:1 set (CMAKE_MODULE_PATH "Findxxx.cmake文件所在的路径" )
CMAKE_MODULE_PATH指定的路径,此时cmake会搜索第二优先级的路径.
如果cmake需要的是Find<name>.cmake,但是没在路径找到,可以添加路径到环境变量:1 set (CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH} "Findxxx.cmake文件所在的路径" )
config 模式 如果按照module模式未找到,cmake将会查找 <Name>Config.cmake 或 <lower-case-name>-config.cmake 文件。cmake会优先搜索自定义的xxx_DIR路径。如果在CMakeLists中没有下面的指令:1 set (xxx_DIR "xxxConfig.cmake文件所在的路径" )
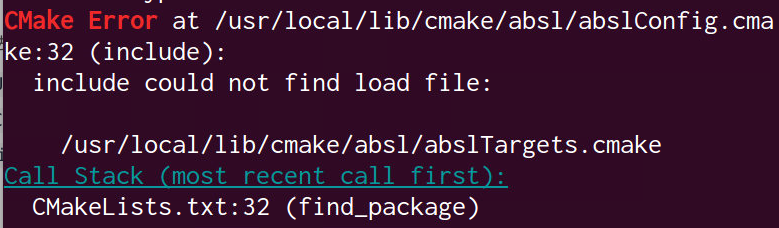
/usr/local/lib/cmake/xxx/中搜索,比如/usr/local/lib/cmake/yaml-cpp/yaml-cpp-config.cmake,如果还没有就失败了。一般情况下,对第三方库执行make install都会把cmake文件放到这个文件夹里,如果编译报错就需要找到文件然后手动复制过去,但是不是光复制xxxConfig.cmake,还要有xxxTargets.cmake,否则find_package就会报错:
上面两种添加路径到环境变量的方法要根据寻找的文件进行设置,比如我在QtCreator+Cmake中使用OpenCV,直接find_package(OpenCV REQUIRED)会报错 找不到OpenCVConfig.cmake ,先用locate尝试寻找FindOpenCV.cmake和OpenCVConfig.cmake,发现只有电脑上只存在后者,所以要用config模式: set(OpenCVDIR "/opt/ros/kinetic/share/OpenCV-3.3.1-dev")
优先级最高的强制方法: </font>
1 find_package(OpenCV REQUIRED PATHS /usr/local /share/OpenCV NO_DEFAULT_PATH)
相关的宏 cmake找到任意一个之后就会执行这个文件,然后这个文件执行后就会设置好一些cmake变量。比如下面的变量(NAME表示库的名字,比如可以用Opencv 代表Opencv库):1 2 3 4 <NAME>_FOUND <NAME>_INCLUDE_DIRS or <NAME>_INCLUDES <NAME>_LIBRARIES or <NAME>_LIBRARIES or <NAME>_LIBS <NAME>_DEFINITIONS
我们可以在CMakeList中用下面代码检验find_package的结果:1 2 3 4 5 6 7 8 9 10 11 find_package(but_velodyne REQUIRED) if (but_velodyne_FOUND) MESSAGE (STATUS "definitions: ${ButVELODYNE_DEFINITIONS}" ) MESSAGE (STATUS "include dirs: ${ButVELODYNE_INCLUDE_DIRS}" ) MESSAGE (STATUS "lib dirs: ${ButVELODYNE_LIBRARY_DIRS}" ) include_directories(${ButVELODYNE_INCLUDE_DIRS}) target_link_libraries (helloworld ${ButVELODYNE_LIBRARY_DIRS}) else () MESSAGE (STATUS " but_velodyne not found" ) endif(but_velodyne_FOUND)
如果cmake在两种模式提供的路径中没有找到对应的Findxxx.cmake和xxxConfig.cmake文件,此时系统就会提示最上面的那些错误信息。
ROS中的find_package 对于catkin_make,它会搜索ROS Package的安装目录,不必用set指定搜索目录.比如std_msgs对应的文件路径在/opt/ros/kinetic/share/std_msgs/cmake/std_msgsConfig.cmake.这两个文件是库文件安装时自己安装的,将自己的路径硬编码到其中。
ROS中常常需要多个package,比如roscpp,rospy,std_msgs。我们可以写成:1 2 find_package(roscpp REQUIRED) find_package(std_msgs REQUIRED)
1 2 3 4 find_package(catkin REQUIRED COMPONENTS roscpp std_msgs )
catkin_INCLUDE_DIRS,这样我们就可以用这个变量查找需要的文件了,最终就只产生一组变量了。.cmake模块中的 NAME_FIND_REQUIRED 变量。
COMPONENTS参数:在REQUIRED选项之后,或者如果没有指定REQUIRED选项但是指定了COMPONENTS选项,在它们的后面可以列出一些与包相关(依赖)的部件清单
编译ROS工作空间的问题
ROS的工作空间用的时间一长,就会创建很多package,有些package的编译又用到了其他的package,这时单纯使用catkin_make就会出现问题。比如package A用到了B,B里又用到了C。即使catkin_make --pkg也不行,因为它会把所有的package都处理一遍,此时处理到A时就会报错,会显示找不到B和C的cmake文件。它们的路径在devel/share/B/cmake
比较笨的方法就是在A的CMakeLists里先把B和C注释掉,同样在B的CMakeLists里把A注释掉,先用catkin_make --pkg C编译C,再依次编译B和A。
找了好长时间没找到很好的解决方法,最后只能预先编译好cmake文件放到SVN上,以后就算B和C的程序改变,也可以编译。
Qt库的情况 以上问题都还简单,问题是在ROS中调用Qt的情况,以Core模块为例,我们有下面的代码:1 2 3 4 5 6 7 8 find_package(Qt5 COMPONENTS Core Xml) target_link_libraries(bin Qt5::Core Qt5::Xml) if (Qt5Core_FOUND) MESSAGE(STATUS "##### ${Qt5Core_VERSION}" ) MESSAGE(STATUS "##### ${Qt5Core_INCLUDE_DIRS}" ) MESSAGE(STATUS "##### ${Qt5Core_LIBRARIES}" ) endif(Qt5Core_FOUND)
运行结果是:1 2 3 -- 5.5.1 -- /usr/include/x86_64-linux-gnu/qt5/; /usr/include/x86_64-linux-gnu/qt5/QtCore; /usr/lib/x86_64-linux-gnu/qt5//mkspecs/linux-g++-64 -- Qt5::Core
首先注意:能使用Qt5的CMake最低版本是 3.1.0,Qt库的宏规则实际仍然符合cmake,不同的地方在于不需要`命令,只要target_link_libraries就足够,它会自动添加相应的include directories,compile definitions`等等
Qt5Core对应的cmake文件在Linux上有两个位置:1 2 3 /home/user/Qt5.11 .1 /5.11 .1 /gcc_64/lib/cmake/Qt5Core/Qt5CoreConfig.cmake /usr/lib/x86_64-linux-gnu/cmake/Qt5Core/Qt5CoreConfig.cmake
CMakeLists中起作用的应当是第二个,应当是安装Qt时,在此目录生成了文件.这个路径与环境变量Qt5_DIR相近,在CMakeLists中用MESSAGE函数能看到:/usr/lib/x86_64-linux-gnu/cmake/Qt5
Boost Boost比较特殊,cmake对它有特别照顾,使用命令cmake --help-module FindBoost可以看到极为详细的使用方法.使用Boost有时要加上REQUIRED COMPONENTS XXX,这是在搜索已经编译的库,但不会检查只有头文件的库.比如thread和system要加入COMPONENTS但asio不需要.
cmake中使用Boost的filesystem,thread模块:1 2 3 4 5 6 7 find_package(Boost COMPONENTS system filesystem thread REQUIRED) target_link_libraries(mytarget ${Boost_FILESYSTEM_LIBRARY} ${Boost_SYSTEM_LIBRARY} ${Boost_THREAD_LIBRARY} )
system模块
pkg_check_modules pkg_check_modules是 CMake 自己的 pkg-config 模块的一个用来简化的封装:你不用再检查 CMake 的版本,加载合适的模块,检查是否被加载,等等,参数和传给 find_package 的一样:先是待返回变量的前缀,然后是包名(pkg-config 的)。这样就定义了<prefix>_INCLUDE_DIRS和其他的这类变量,后续的用法就与find_package一致。
当安装某些库时(例如从RPM,deb或其他二进制包管理系统),会包括一个后缀名为 pc 的文件,它会放入某个文件夹下(依赖于系统设置,例如,Linux 为该库文件所在文件夹/lib/pkgconfig),并把该子文件夹加入pkg-config的环境变量PKG_CONFIG_PATH作为搜索路径。pkg_check_modules实质上是检测系统中的 pkg-config 是否存在指定的 .pc 文件。
在我的电脑上执行echo $PKG_CONFIG_PATH,结果是:1 /home/user/Robot/workspace/devel/lib/pkgconfig:/opt/ros/kinetic/lib/pkgconfig:/opt/ros/kinetic/lib/x86_64-linux-gnu/pkgconfig
在bash.rc里没有设置,但是能获得这个环境变量,这是因为我们的环境变量里设置了1 2 source /opt/ros/kinetic/setup.bash source /home/user/Robot/workspace/devel/setup.bash
pkg_check_modules时,就会去上面的路径里搜索pc文件,例如1 2 3 4 # bfl (Bayesian Filtering Library)是一个使用pkg-config的第三方库 # 先搜索cmake自己的PkgConfig模块,才能使用pkg_check_modules find_package (PkgConfig) pkg_check_modules (BFL REQUIRED orocos-bfl)
PkgConfig的路径在/opt/ros/kinetic/share/ros/core/rosbuild/FindPkgConfig.cmake
搜索对应库文件,发现在以下路径:1 2 /opt/ros/kinetic/lib/liborocos-bfl.so /opt/ros/kinetic/lib/pkgconfig/orocos-bfl.pc
现在我们可以获得对应的宏,使用这个库了:1 2 include_directories(${BFL_INCLUDE_DIRS}) link_directories(${BFL_LIBRARY_DIRS})
参考:CMake Manual For Qt Boost的编译库列表