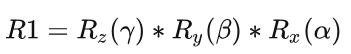多行注释
bash脚本的多行注释可以采用HERE DOCUMENT特性,实现多行注释,比如1
2
3
4<<'COMMENT'
...
COMMENT
举例如下:1
2
3
4
5
6
7
8
echo "Say Something"
<<COMMENT
your comment 1
comment 2
blah
COMMENT
echo "Do something else"
将命令执行的结果写入日志文件
catkin_make > make.log, 注意不要用一直执行的命令,比如ping
head与tail
tail -f showMapInfo.log可以实时显示文件的更新tail -n 5 showMapInfo.log显示文件最后5行head -n 5 showMapInfo.log显示文件开始5行
修改指定目录下的所有文件的权限
全体可读、可修改、可执行: chmod -R 777 dir
history
使用history列出历史命令后,如果需要执行第 1024 历史命令,可以执行 !1024
如果以前执行了一个很长命令,只记录命令开头是 curl,这时就可以通过 !curl 快速执行该命令。但是执行的可能不是我们需要的,所以常常加上 :p,即 !curl:p ,打印出了搜索到的命令,如果要执行,请按 Up 键,然后回车即可。
在命令前额外多加一个空格,这样的命令是不会被记录到历史记录的
执行文件
对于可执行文件,在当前目录时用命令./file即可,如果是完整绝对路径,就用命令/path/file即可
检测温度
开始检测硬件传感器:sudo sensors-detect
要确保已经工作,运行命令:sensors,但只运行一次
设置终端初始路径
在bashrc中加一行: cd PATH即可
有一次发现不管怎么改也没用,按照网上的方法修改bash_profile不奏效。 后来发现是系统环境变量$HOME被改变了,于是在/etc/profile中添加一行 export HOME=/home/user,问题解决
显示当前目录的文件和目录,按大小列表排序
ls -Slrh
如果排除目录: ls -Slrh | grep -v '^d'
当前目录下占用最大磁盘空间的目录
1 | du -ahx . | sort -rh | head -5 |
Linux 踢出其他正在 SSH 登陆用户
查看系统当前所有在线用户: w1
2
3
414:15:41 up 42 days, 56 min, 2 users, load average: 0.07, 0.02, 0.00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 116.204.64.165 14:15 0.00s 0.06s 0.04s w
root pts/1 116.204.64.165 14:15 2.00s 0.02s 0.02s –bash
查看当前自己占用终端1
2[root@apache ~]# who am i
root pts/0 2013-01-16 14:15 (116.204.64.165)
用 pkill 命令踢掉对方: pkill -kill -t pts/1
再用 w 命令在看看踢掉没有,如果最后查看还是没有踢掉,加上 -9 强制杀死。
反向删除
文件夹下,删除abc文件以外的所有文件1
ls | grep -v ^abc$ | xargs -i rm -rf {}
如果abc不加正则表达式,会保留文件名包含abc的文件,比如abcd。
对当前目录下的所有文件排序
du -s *. | sort -nr
显示当前目录的最大的文件
du -s *. | sort -nr | head -1
检查系统中的设备情况
需要检查日志 /var/log/messages
只显示文件名和大小
ls -sh .显示当前文件夹的所有文件大小du -sh folder显示指定文件夹或文件的大小,结果容易可读,比如4G。
du -s /home/user/.ros/log的执行结果为1
1147000 /home/user/.ros/log
大小的单位为 K。
如果只取空格左边部分,使用 echo $(du -s /home/user/.ros/log) | cut -d " " -f 1,如果取空格右边部分,那么把1改为2.
ls -Slrh显示当前目录的文件和目录,按大小列表排序。如果排除目录:ls -Slrh | grep -v '^d'
获取CPU核数
getconf _NPROCESSORS_ONLN 2>/dev/null || sysctl -n hw.ncpu || echo 1
tar.gz 压缩
把file.txt文件压缩成file.tar.gz: tar -zcvf myfile.tar.gz myfile.txt
删除包含字符串的行
把文件中包含某字符串的行删掉,比如下面文件中的abc所在行删除,使用sed命令:1
2
3
4
5
6
7
8abc12
abc402
a213bc
dlifjljs
abc
904650-9
aabbcc
123abc53465
经过sed处理,变为1
2
3
4a213bc
dlifjljs
904650-9
aabbcc
如果执行sed -e '/abc/d' test.txt,只显示修改后的结果,未修改文件。如果执行sed -i,修改并保存文件。
延时函数
使用 sleep 或usleep函数。只看sleep函数:1
2
3
4
5#参数单位默认为秒。
sleep 1s 或 sleep 1 #表示延迟一秒
sleep 1m #表示延迟一分钟
sleep 1h #表示延迟一小时
sleep 1d #表示延迟一天
xargs
xargs 是给命令传递参数的一个过滤器,也是组合多个命令的一个工具。它能够捕获一个命令的输出,然后传递给另外一个命令。
xargs 可以将管道或标准输入数据转换成命令行参数,这是最常用的场合,也能够从文件的输出中读取数据。
比如执行命令find *.sh,结果如下:1
2
3
4
5deb软件安装.sh
Kinetic插件安装.sh
ping.sh
ubuntu初始化精简版.sh
所有alias.sh
执行find *.sh | xargs会将多行结果变为单行:1
deb软件安装.sh Kinetic插件安装.sh ping.sh ubuntu初始化精简版.sh 所有alias.sh
执行find *.sh | xargs ls -smh会使xargs捕获find结果,然后传递给之后的命令做参数,这是管道做不到的,结果:1
2
34.0K deb软件安装.sh, 4.0K Kinetic插件安装.sh,
4.0K ping.sh, 4.0K ubuntu初始化精简版.sh,
4.0K 所有alias.sh
xargs与管道不同,首先看命令echo test.cpp,结果是test.cpp.再看命令echo test.cpp | cat,结果还是test.cpp,这是管道将echo的结果定向为cat的输入,执行cat当然还是那个结果.但是echo test.cpp | xargs cat就不一样了,xargs将test.cpp做cat的命令参数,也就是第二次执行的是cat test.cpp
修改某文件的修改时间
1 | touch -t 201905171210.20 test.py # 指定新时间 |
查看进程PID及线程
pidof chrome显示所有进程的pid,进程名必须完整pgrep sublime通过名字获取pid,可以是部分进程名ps -T -p pid进程的子进程情况
pkill kill killall
kill pid按pid杀死进程kill -9 pid按pid强制终止进程,但是可能造成数据丢失,轻易不要使用。比如kill -9 $(pgrep rosmaster)killall name按名称杀死一个进程组的所有进程,比如killall chrome杀死所有的chrome进程pkill name按名称终止包含name的所有进程pkill -o chrome杀死最旧的chrome进程pkill -n chrome杀死最新的chrome进程pkill -c chrome杀死所有chrome进程,同时显示数量
用脚本杀死阻塞的进程
1 |
|
command是一个阻塞的进程,只有按下ctrl+C后才能继续运行,但在这种循环的情况,显然不能一直去按ctrl+C,所以需要脚本去终止进程command,也就是kill -2 $!
杀死终端的进程
ubuntu终端的进程名为bash,如果在自己电脑pkill bash,还会剩下当前操作的终端,其他的全关。如果通过另一台电脑远程登录,执行pkill bash,可以将所有终端关闭。
xdotool
sudo apt-get install -y xdotool
- 最小化当前窗口:
xdotool windowminimize $(xdotool getactivewindow)
还有很多功能,这个工具能模拟鼠标键盘的大量操作,可参考 神器 xdotool
带参数的alias
有时需要运行一个带参数的很长的命令,这样感觉很不方便,可以与alias结合,提高效率。alias不支持直接加参数,而是通过函数来间接实现。1
2# test()是个函数
alias ldd='test() { ldd $1 | grep -v kinetic | grep -v x86_64-linux-gnu;}; test'
统计文件行数、字节、字数
wc命令,选项 -l, -c, -w 分别统计行数、字节、字数,可统计多个文件,但不能统计目录。1
2
3wc -c main.cpp
wc -l *.cpp
wc -l main.cpp test.cpp t.cpp //统计三个文件行数
只显示文件名和日期
1 | ls -lSh | awk '{print $6,$7," " $8," " $9}' |
统计目录中的文件个数 (包括文件夹)
ls | wc -l
当前文件夹或文件大小
当前文件夹:du -smh
当前文件夹下所有文件和子文件夹: du -mh .
某文件: du -smh file
当前目录下大于400M的文件夹和文件,并从小到大排序1
sudo du -h | grep "[4-9][0-9][0-9]M" | sort -n
ls -lht frames.pdf 显示文件的详细信息,比如:1
-rw-rw-r-- 1 user user 20K 6月 29 10:24 frames.pdf
时间相关
date -s "2024-10-15 15:50:00"设置时间date +%s输出UTC时间
判断文件/文件夹是否存在
1 | if [ -d ~/Documents/dir ] |
-d判断后面的文件夹是否存在-f判断是否存在某文件-s判断是否存在某文件,且大小不为0,这个比-f更有用
函数
组合多个命令到一个操作。下面的命令组合了 mkdir 和 cd 命令。输入 mc folder_name可以在你的工作目录创建一个名为folder_name的目录并立刻进入1
2
3
4mc () {
mkdir -p $1
cd $1
}
scp出错
使用scp传递文件时,出现了这样的报错: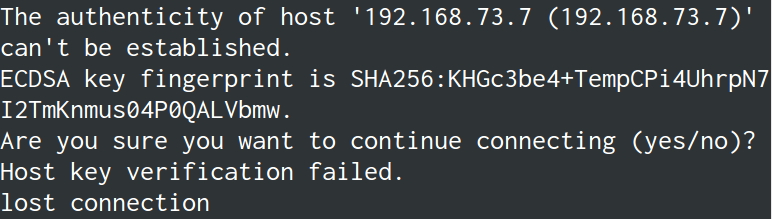
解决方法: ssh -o StrictHostKeyChecking=no 192.168.73.14
注意: 这里的IP是发送者的IP
自动化工作
每次本机提交代码后,远程再更新,编译和移动可执行文件,过程比较繁琐,干脆都放到一个Shell脚本里,用alias执行这个脚本1
2
3
4
5
6
7cd /home/user/Robot/workspace/src
svn up
cd /home/user/Robot/workspace
catkin_make --pkg package1 package2 package3
cp $packagebin"/exe1" $dir
cp $packagebin"/exe2" $dir
用echo管道命令给sudo自动输入密码
1 | echo password | sudo -S cmd |
-S表示从标准输入读取密码。这样用于system函数就比较方便了,但是这种方式密码会明文显示,密码不安全
拆分大文件
用split命令拆分大文件,以原本文件名为前缀,数字为后缀
1 | split --verbose -n5 myfile.cpp -d myfile_ |
把myfile.cpp分割为5个文件, 以myfile_为前缀, 显示分割过程,但是缺陷在于拆分的文件没有扩展名
进一步优化:把test.log拆分,每个最大200k,并且按照test_数字命名,带扩展名。split test.log -b 200k -d -a 2 test_&&ls | grep test_ | xargs -n1 -i{} mv {} {}.log
升级版ping命令
当能ping通一个主机时,此时ping命令会一直执行,要想终止,可采用CTRL+c或CTRL+z方式退出。也可以设置选项方式,使得ping命令执行若干次包就终止。ping -c 4 ip,此时ping命令将执行4次
下面的脚步是执行ping命令时,可以只输入最后地址1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#/bin/bash
ip=`hostname -I`
net=$(cut -d'.' -f3<<<$ip)
var1=$(cut -d'.' -f1<<<$ip)
var2=$(cut -d'.' -f2<<<$ip)
sub=${var1}'.'${var2}'.'${net}'.'
echo -e "\033[41;37m 输入要ping的IP最后一个地址 \033[0m"
read -p ":" addr
address=${sub}${addr}
ping -c 3 $address
echo -e "\033[44;37m Ping IP address done ! \033[0m"
当前文件夹中只有一个子目录时,直接进入
可以做成alias ccd :1
2
3
4
5
6
7
8
9
10
11#/bin/zsh
n=$(ls | wc -l)
if [ "$n" -eq "1" ]
then
folder=$(ls)
cd $folder
else
echo "can't cd, more than 1 child folder"
fi
当前文件夹中只有一个文件时,直接用vim打开
1 |
|
使用脚本在当前终端打开一个新标签
1 | gnome-terminal --tab |
在终端中打开多个tab,每个tab运行单独的命令
1 | title1="tab 1" |
linux删除某文件以外的文件
1 | rm -f !(a) |
找出当前文件夹下大于100M的文件
1 | find . -type f -size +100M -print0 | xargs -0 du -h | sort -nr |
只显示当前所有文件的名称和大小
1 | ls -smhSlr | awk '{ print $1, $10 }' |
判断当前某进程的个数或是否在运行
1 |
|
Linux 踢出其他正在 SSH 登陆用户
查看系统当前所有在线用户: w1
2
3
414:15:41 up 42 days, 56 min, 2 users, load average: 0.07, 0.02, 0.00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 116.204.64.165 14:15 0.00s 0.06s 0.04s w
root pts/1 116.204.64.165 14:15 2.00s 0.02s 0.02s –bash
查看当前自己占用终端1
2[root@apache ~]# who am i
root pts/0 2013-01-16 14:15 (116.204.64.165)
用 pkill 命令踢掉对方: pkill -kill -t pts/1
再用 w 命令在看看踢掉没有,如果最后查看还是没有踢掉,加上 -9 强制杀死。