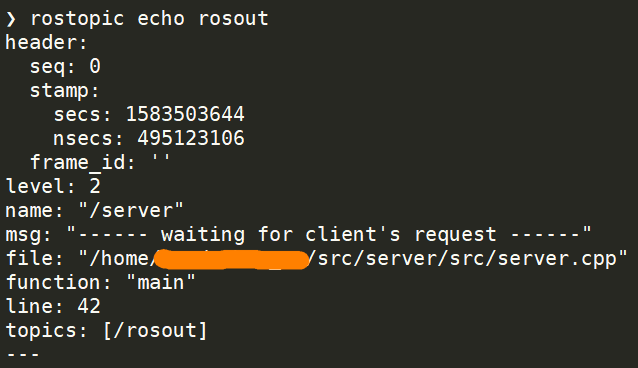
For frame [tag_9]: No transform to fixed frame [/map]. TF error: [Could not find a connection between 'map' and 'tag_9' because they are not part of the same tree.Tf has two or more unconnected trees.]
现在执行INSTALL命令不再是sudo make install了,而是catkin_make install,它相当于:
1 2 3 4 5
cd ~/catkin_ws/build # If cmake hasn't already been called cmake ../src -DCMAKE_INSTALL_PREFIX=../install -DCATKIN_DEVEL_PREFIX=../devel make make install
message(STATUS "12345") #如果不加STATUS,不会在前面加--标志 message(STATUS " include dirs: ${catkin_INCLUDE_DIRS}" ) #有一个--开头 message(STATUS " include dirs:"${catkin_INCLUDE_DIRS} ) # 同上面等价
除了最常用的STATUS还有下面可使用的参数
(无) = 重要消息;
WARNING = CMake 警告, 会继续执行;
AUTHOR_WARNING = CMake 警告 (dev), 会继续执行;
SEND_ERROR = CMake 错误, 继续执行,但是会跳过生成的步骤;
FATAL_ERROR = CMake 错误, 终止所有处理过程;
比如使用message(WARNING "Compiler not supported C++ 20 standard"),出现下面结果
1 2
CMake Warning at ros/src/lqr_steering/CMakeLists.txt:15 (message): Compiler not supported C++ 20 standard
换成AUTHOR_WARNING会出现下面结果
1 2 3
CMake Warning (dev) at ros/src/lqr_steering/CMakeLists.txt:15 (message): Compiler not supported C++ 20 standard This warning is for project developers. Use -Wno-dev to suppress it.
如果在执行cmake时,遇到一个错误情况需要停止执行,可以用FATAL_ERROR:
1 2 3
if( SOME_COND ) message( FATAL_ERROR "You can not do this at all, CMake will exit." ) endif()
int snprintf(char *restrict buf, size_t n, const char * restrict format, ...); 函数说明:最多从源串中拷贝n-1个字符到目标串中,然后再在后面加一个0。所以如果目标串的大小为n的话,将不会溢出。 函数返回值:若成功则返回欲写入的字符串长度,若出错则返回负值。
1 2 3 4 5 6 7 8 9
char s1[6] = "12345"; char s2[6] = "67890"; int res; res = snprintf(s1,sizeof(s1),"abcdefg"); //写入长度大于原来长度,写入abcde和\0,要求6 printf("s1:%s, res:%d\n",s1,res); //欲写入长度7,这个值是strlen,不包含\0 res = snprintf(s1,sizeof(s1),"abc"); //写入长度少于原来长度,则相当于替换 printf("s1:%s, res:%d\n",s1,res); res = snprintf(s2,4,"%s","abcdefg"); //指定4,包含了\0 printf("s2:%s, res:%d\n",s2,res);
Point p(1,4); //改变 p p[0] = 7; p[1] = 9; Point p1 = -p; Point p2(4,12); Point p3 = p - p2; if(p2==p3) cout<<"equal"<<endl; else cout<<"not equal"<<endl; Point p4 = ++p3; Point p5 = --p3;