大多数雷达都是TOF测量法,只有深度信息,没有相机那样的纹理信息,也就没有视觉SLAM的运算负荷。
目前常见的激光雷达都是旋转扫描式的,内部长期处于旋转中的机械结构会给系统带来不稳定性,在颠簸震动时影响尤其明显。固态激光雷达的逐步成熟可能会为激光SLAM扳回这项劣势。
激光雷达的使用寿命问题已经被解决,能够保证长时间使用不会出现故障。比如在连续工作情况下,RPLIDAR-A2的设计使用寿命可长达5年以上。
雷达的光线遇到大雾、烟尘会受到遮挡,影响性能。
测试材质
选用雷达需要判断雷达是否适用于自己的场合,所以根据需要在以下场景进行测试
大理石瓷砖。 应用场景参考:酒店大堂、走廊、室外墙壁
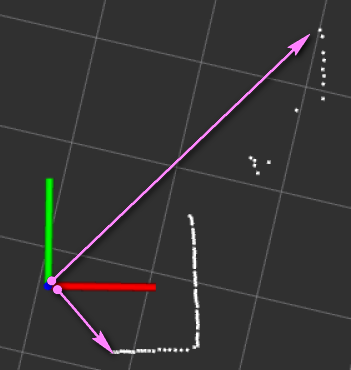
玻璃。 应用场景参考:玻璃门窗,办公大厅、玻璃柜台。 激光会穿过透明玻璃,从而造成一定概率的漏检。可以增加一些辅助反射手段,比如粘贴磨砂贴纸,或配合其他非光学的传感器作为补充。 雷达有时会穿透玻璃,有时不会,所以临时在玻璃上贴磨砂纸。
不锈钢板。 应用场景参考:电梯、生产车间、港口码头
反光条。 应用场景参考:医院、生产车间、酒店大堂
误差源
发送和接收激光束的精确耗时误差,也就是计时设备的精度问题
目标材质的反射值特性,比如全黑的材料吸收了光的大部分能量,使得反射量极低;或者像镜子一样的材料会将大部分光反射到其它地方
运动畸变:由于激光雷达在跟随自动驾驶车辆前进的同时,对周围环境进行扫描建模,也就是说车辆相对于周围的环境是运动的,导致对环境测量的实际位置与真实位置存在偏差。但是扫描频率高,速度低时,可以不必考虑。
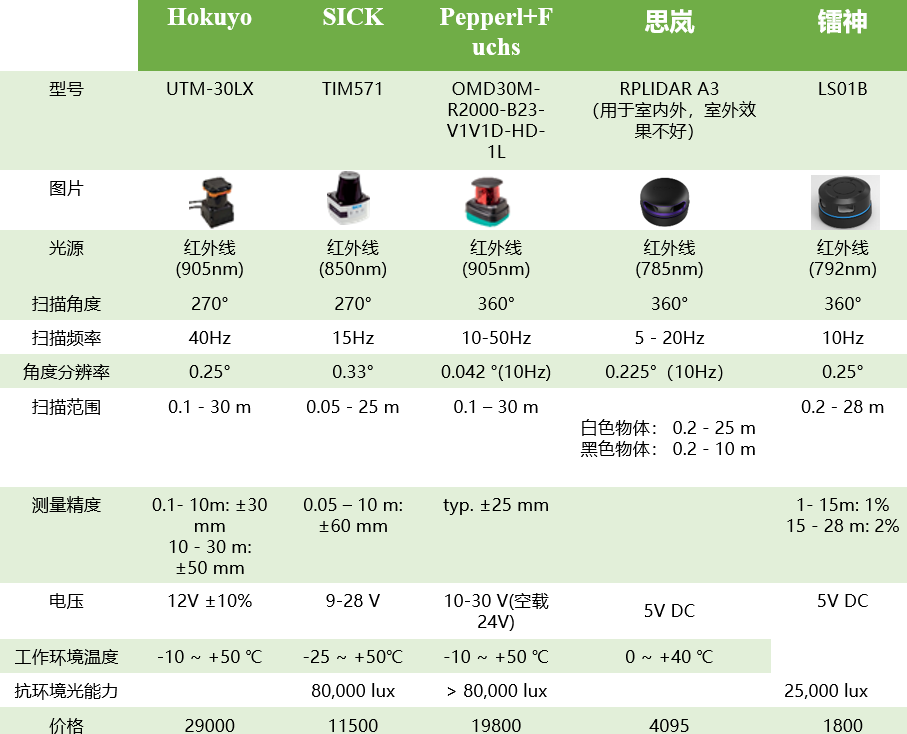
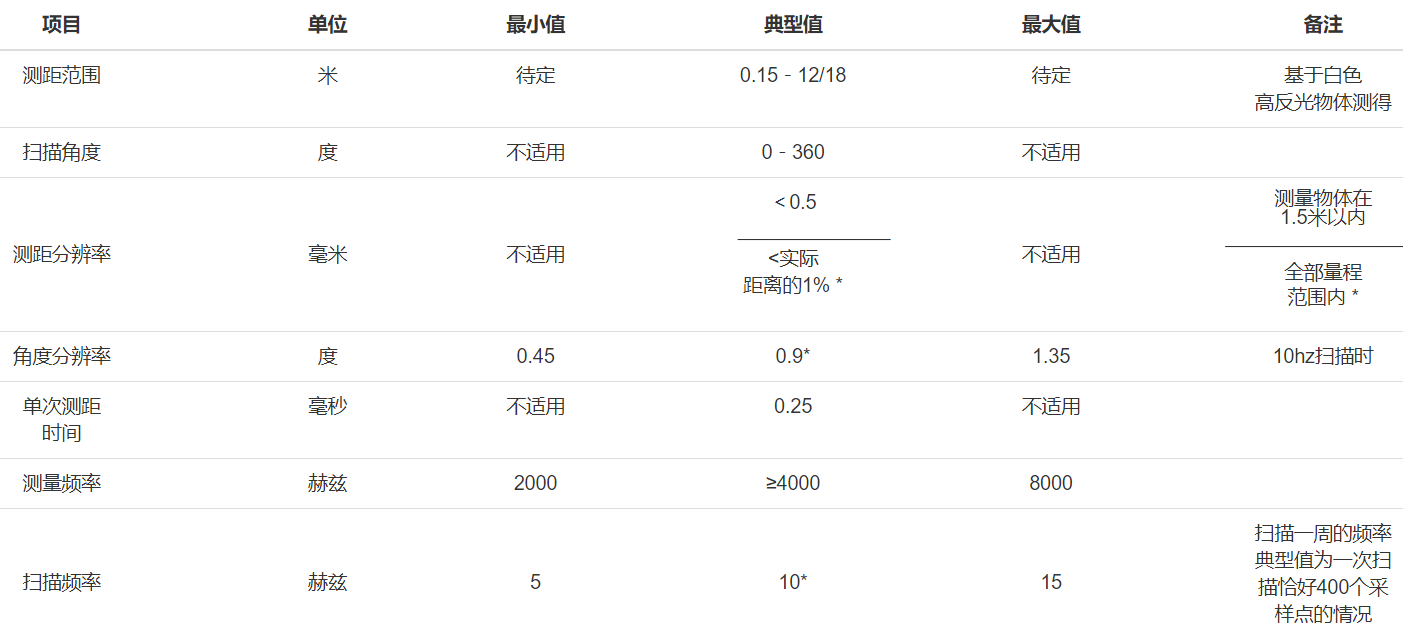
测距范围
指雷达能够测量的距离范围。如果实际障碍距离超出最大值,那么雷达数据会标记为无效点(不是距离为0)。市面上2D雷达最近距离也至少几厘米
实际情况下,雷达测距的最大值有可能因为工作环境而产生变化。雷达要想测距,需要接收到反射的激光。所以官方在测距范围这一项上添加了备注:“基于白色70%反射率物体”。
如果是吸收激光比较厉害的物体,例如黑色的表面又几乎不反光的物体,会导致反射光强度很弱,那么距离稍微远点,可能就测距失败了,这时候,该物体即使在标出的12米范围内同样无法测出。针对类似这样的物体,相当于实际测距的最大值变小了。透明的玻璃也是同样原因。
不过因为不同的物体和环境差异太大了,所以厂商也不太可能将全部情况测试一遍,更多的时候需要靠自己来实验,看是否能够适用实际的工作环境。
扫描角度
思岚雷达是360°扫描的。有些雷达例如SICK的一些雷达,扫描角度只有220°。 实际使用,通常也不需要完全的360°,特别是雷达放在结构的中间层,因为有结构固定装置的存在,必然会有遮挡。
测距分辨率
分辨率和精度是两个不同的概念,按照上述参数的意思,更准确来说应该指的是测距精度。
RPLIDAR的精度并不是恒定的一个百分比,简单的解释是,距离越远,反射光受到的干扰越大,自然精度下降了。实际上,不同批次的雷达精度之间也有一定的差异。正因为这些不确定性,官方文档给的是较保守的值。
1.5m范围内小于0.5mm的精度还是可以的,1.5米处约为万分之三点三。
当在最大距离12米的时候,如果精度下降到最差的1%,则误差为0.12m,也能接受。
扫描频率

衡量雷达一秒钟能转多少圈,直接改叫雷达转速也是可以的。
转速实际上跟雷达数据更新周期是挂钩的,比如说典型的10Hz,那就是说转一圈的时间大概是100ms,那么雷达数据差不多也是100ms一帧。 要跟scan话题的发布频率区分开,后者跟计算机性能有关。
LMS1xx系列的扫描频率是25~50Hz,角度分辨率为0.25°~0.50°
LMS5xx系列的扫描频率是25~100Hz,角度分辨率为0.1667°~1°
雷达自身的旋转是有方向的,大部分雷达都是逆时针旋转,与ROS中规定的一样,也有少部分雷达是顺时针旋转的,只不过使用起来有点不方便。
角度分辨率
正常来说,雷达转一圈,这一圈得到的测量点是均匀分布的,每个点之间间隔的角度就是所谓的角度分辨率了。
角度分辨率越小说明雷达转一圈得到的点数越多。例如,角度分辨率是0.45,则一圈是800个点,角度分辨率是0.9,则一圈是400个点。
不过,实际的角度分辨率其实不一定是固定的,即两个点之间的间距不一定是相同的,不过都在给出的分辨率范围内。在ROS中,雷达数据的标准格式认为角度分辨率是固定的,为了符合ROS标准,雷达的ROS驱动实际上做了角度补偿,将输出点修正为均匀分布的。
数据的强度
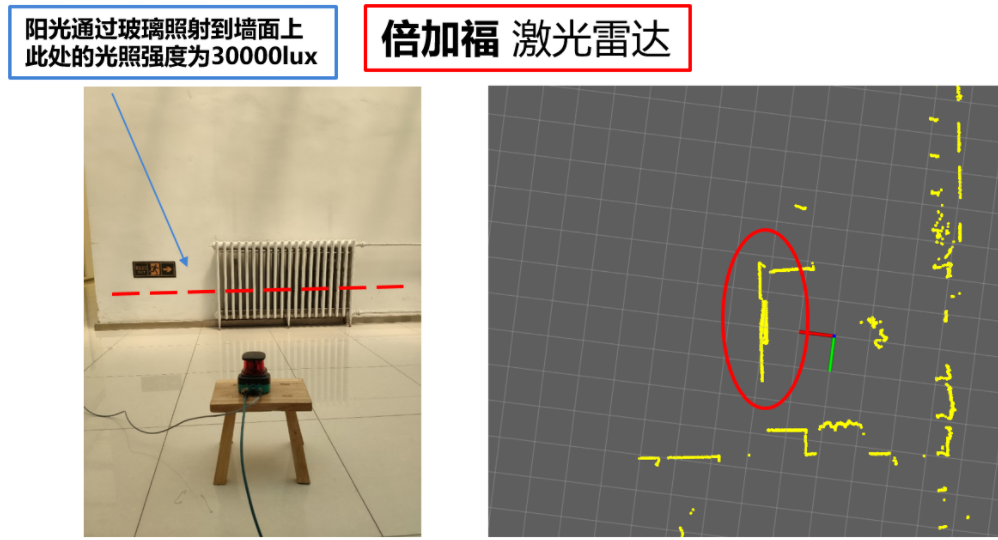
激光雷达的激光点是有能量的,不同品牌激光点的能量也不同。当能量太小时,远距离情况下可能存在返回不了数据的情况。
可以等阳光或者使用光束照射到墙面上,激光雷达再去看被光照射到的墙面,对比这时的点云效果。可以用照度仪测量此时的光强度。倍加福雷达的点云效果在高强度情况下非常好,不愧是用于反光板的雷达。
数据的精度
这是最重要的一个指标,表示激光雷达的数据跳动情况。现在一般厂商的雷达的精度都是2%。也就是100m的情况下,点的跳动幅度为2cm。但是,实际感觉能达到这个精度的雷达不是很多。
multi-echo
multi-echo可以分析每个测量光束的两个回波信号,这样在雨雪天可以提供可靠的测量结果。一般激光打到玻璃上会有部分穿透,导致测量不准,multi-echo使激光从玻璃上返回来,还能从玻璃后面的墙上返回来。
有的雷达具备这种特性,比如SICK-LMS111
参考:
从零开始搭二维激光SLAM —- 激光雷达数据效果对比
LakiBeam1雷达