
cartographer_ros节点main函数所在的称为main线程,其它的称后台线程。PoseGrapher::AddNode在main线程,但计算两种约束、优化全局位姿都在后台线程。
PoseGraph有一个线程池,配置一定数量的线程来执行优化任务。线程池在MapBuilder构造函数中创建,作为参数给PoseGraph对象,PoseGraph将其作为 constraints::ConstraintBuilder2D的初始化使用。每个线程执行 ThreadPool::DoWork()函数。 DoWork()函数会一直循环遍历一个deque队列中的Task任务,每次执行完一个Task,就会从队列弹出。 即std::deque<std::shared_ptr<Task> > task_queue_
这个task_queue_的添加任务追溯到线程池的Schedule函数,Schedule函数在PoseGraph2D::AddWorkItem和添加约束的函数里
每次收到SLAM需要的信息都会生成一个work,这个work都会保存到PoseGraph的work_queue_队列中,上面说的task通过SetWorkItem进一步执行DrainWorkQueue, 进而从 work_queue_中取出 WorkItem 执行。这些 WorkItem 是由pose_graph添加各种传感器数据和 Node的时候加入到该队列的,比如AddImuData
lambda 和 仿函数
看work_queue_队列之前,先要搞清lambda 和 仿函数是怎么回事。
先看一个简单的仿函数1
2
3
4
5
6
7int add(float a, float b)
{
return a+b;
}
// int是返回值类型,括号里是参数的类型
std::function<int(float, float)> func = add;
cout<< func(2.4, 6.9) <<endl;
lambda表达式通常仅仅是仿函数的语法糖,可以直接转换为仿函数。[]中的任何内容都会转换为构造函数参数和仿函数对象的成员,而()中的参数将转换为仿函数operator()的参数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19void AddWorkItem(std::function<int()>& work_item)
{
cout << work_item() <<endl;
}
void AddImuData(int a, int b)
{
// []:默认不捕获任何变量
// [=]:默认以值捕获所有变量
// 其实可以用 auto
std::function<int()> func = [=](){
cout <<"input: "<< a << " "<< b<< endl;
return a+b;
};
// std::function<int(float,float)> func2 = add;
AddWorkItem( func );
}
// main 函数中调用
AddImuData(29, 7);
把cartographer中的函数做了修改,这样容易理解。 main 函数中调用AddImuData,我们要的是运行lambda表达式,假如AddWorkItem是空函数,那么不会有运行结果。work_item()才是实际的运行lambda表达式。
workqueue 机制
PoseGraph2D有16个成员函数调用了AddWorkItem,也就是加入了work_queue_队列。操作work_queue_的函数主要是AddWorkItem 和 DrainWorkQueue
以PoseGraph2D::AddImuData为例:1
2
3
4
5
6
7
8
9
10
11
12
13void PoseGraph2D::AddImuData(const int trajectory_id,
const sensor::ImuData& imu_data)
{
AddWorkItem( [=]() LOCKS_EXCLUDED(mutex_)
{
absl::MutexLock locker(&mutex_);
if (CanAddWorkItemModifying(trajectory_id)) {
optimization_problem_->AddImuData(trajectory_id, imu_data);
}
return WorkItem::Result::kDoNotRunOptimization;
}
);
}
后面会看到AddWorkItem的参数是一个仿函数std::function。 AddImuData实际上就一句,也就是调用了AddWorkItem, 这里面的AddWorkItem的参数其实是把一个lambda表达式作为仿函数,这个仿函数的返回值是WorkItem::Result,实际是枚举值kDoNotRunOptimization 或者 kRunOptimization
1 | // 将一个函数地址加入到一个工作队列中 |
work_queue_的类型是std::unique_ptr<WorkQueue>, WorkQueue是WorkItem的deque。根据上面的分析, 我们要想运行lambda表达式,要的是 work_item(),但是这个函数里没看到,因为这里只有添加,是添加到work_queue_里了。实际的运行在DrainWorkQueue
1 | void PoseGraph2D::DrainWorkQueue() |
上面说了PoseGraph2D有16个成员函数调用了AddWorkItem,但是发现只有3个函数会返回kRunOptimization:FinishTrajectory, RunFinalOptimization和 ComputeConstraintsForNode。
16个里面最重要的当然是后端入口函数PoseGraph2D::AddNode,在它的work_item是ComputeConstraintsForNode, 在ComputeConstraintsForNode的最后部分:1
2
3
4
5
6if (options_.optimize_every_n_nodes() > 0 &&
num_nodes_since_last_loop_closure_ > options_.optimize_every_n_nodes() )
{
return WorkItem::Result::kRunOptimization;
}
return WorkItem::Result::kDoNotRunOptimization;
整个SLAM中实时进入任务队列的主要为计算约束,当加入节点数超过参数时,才进行一次优化。
ConstraintBuilder2D::WhenDone
最后的ConstraintBuilder2D::WhenDone又用到了lambda表达式,又涉及到线程池,实际的后台优化是在HandleWorkQueue。1
2
3
4
5
6
7
8
9
10
11
12
13
14// Result 就是 vector<Constraint>
void ConstraintBuilder2D::WhenDone(
const std::function<void(const ConstraintBuilder2D::Result&)>& callback)
{
absl::MutexLock locker(&mutex_);
CHECK(when_done_ == nullptr);
// 成员 unique_ptr<std::function<void(const Result&)>> when_done_;
when_done_ = absl::make_unique<std::function<void(const Result&)> > (callback);
CHECK(when_done_task_ != nullptr);
// 约束的计算结果通过回调进行回传
when_done_task_->SetWorkItem([this] { RunWhenDoneCallback(); });
thread_pool_->Schedule(std::move(when_done_task_));
when_done_task_ = absl::make_unique<common::Task>();
}
这里实际就是处理when_done_task_,它是在finish_node_task执行完之后才执行的,内容就是HandleWorkQueue
优化执行完毕时的回调函数RunWhenDoneCallback1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28void ConstraintBuilder2D::RunWhenDoneCallback()
{
Result result;
std::unique_ptr<std::function<void(const Result&)>> callback;
{
absl::MutexLock locker(&mutex_);
CHECK(when_done_ != nullptr);
// 将约束结果放入 result
// MaybeAddConstraint 里添加 constraints_
for (const std::unique_ptr<Constraint>& constraint : constraints_)
{
if (constraint == nullptr) continue;
result.push_back(*constraint);
}
if (options_.log_matches() )
{
LOG(INFO) << constraints_.size() << " computations resulted in "
<< result.size() << " additional constraints.";
LOG(INFO) << "Score histogram:\n" << score_histogram_.ToString(10);
}
constraints_.clear();
callback = std::move(when_done_);
when_done_.reset();
kQueueLengthMetric->Set(constraints_.size());
}
// 我理解的 HandleWorkQueue 是在这里
(*callback)(result);
}
scan match的过程如下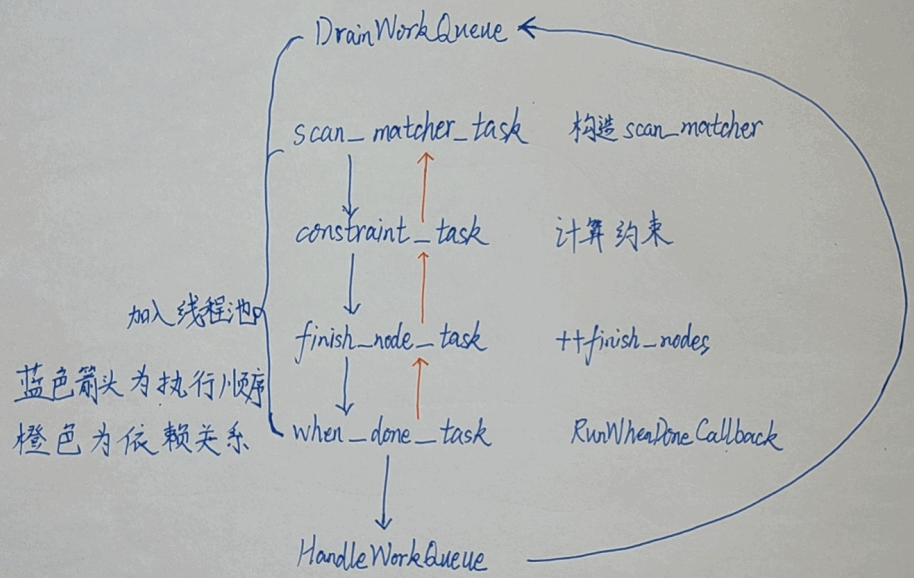
AddImuData等函数不是直接放到线程里运行的,进线程池的是DrainWorkQueue