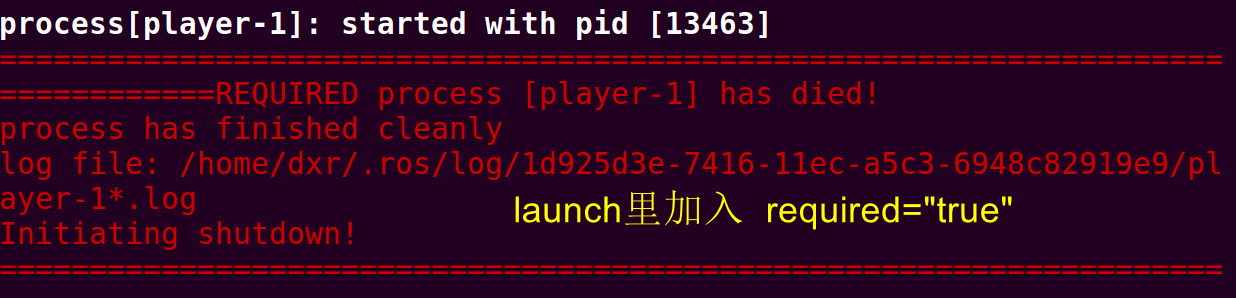
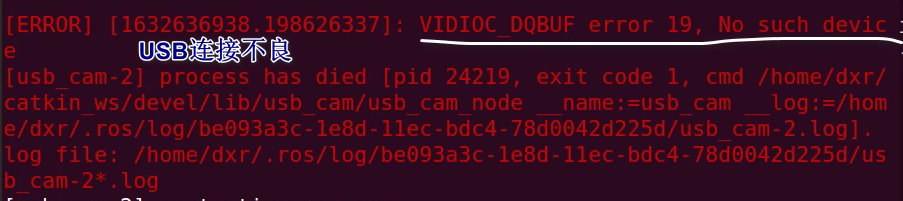
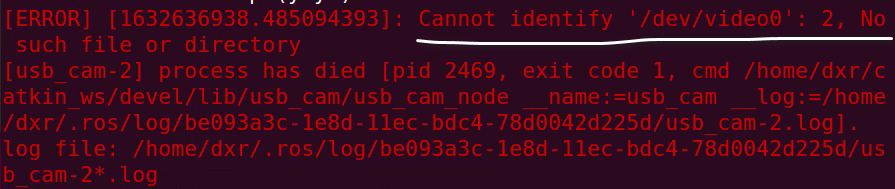
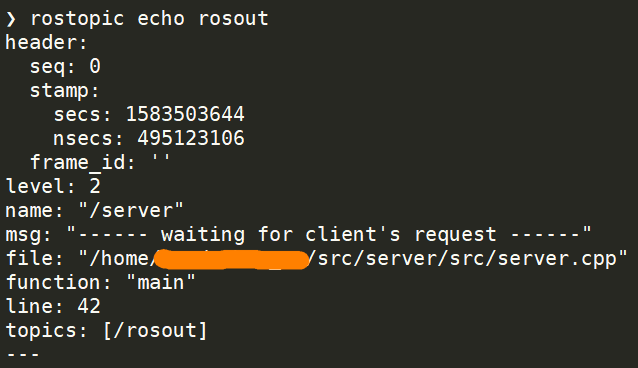
必须有设置的环境变量
- ROS_ROOT
这个是ROS核心包安装路径,也就是/opt/ros/kinetic/share/ros,不须自己设置
- ROS_PACKAGE_PATH
所有ros package所在位置,一般为/home/name/catkin_ws_test/src:/opt/ros/kinetic/share
这几个环境变量一般不需要显式地添加,而是通过运行source /opt/ros/kinetic/setup.bash和source %个人工作空间目录%/devel/setup.bash来进行设置。一般需要将上面这两行命令添加到系统的~/.bashrc文件中,来避免每次开启终端时都要重新手动执行设置命令。
- ROS_MASTER_URI
这个表示主机的IP信息,比如http://192.168.134.123:11311。这个必须要手动设置
- ROS_IP/ROS_HOSTNAME
ROS主从多机协作时使用,用来设置设置不同机器上ROS的网络地址。这个必须要手动设置
执行env | grep ROS会得到如下结果,有些环境变量不设置也会有默认值1
2
3
4
5
6
7
8
9
10
11ROSCONSOLE_FORMAT=[${message}
ROS_ETC_DIR=/opt/ros/melodic/etc/ros
ROS_ROOT=/opt/ros/melodic/share/ros
ROS_MASTER_URI=http://192.168.8.177:11311/
ROS_VERSION=1
ROS_PYTHON_VERSION=2
ROS_IP=192.168.8.177
ROS_PACKAGE_PATH=/home/user/test_nodes/src:/home/user/catkin_ws/src:/opt/ros/melodic/share
ROSLISP_PACKAGE_DIRECTORIES=/home/user/test_nodes/devel/share/common-lisp:/home/user/catkin_ws/devel/share/common-lisp
ROS_HOSTNAME=192.168.8.177
ROS_DISTRO=melodic
可选的环境变量
ROS_VERSION, 比如 1ROS_DISTRO, 比如noeticROS_ETC_DIR
比如 /opt/ros/noetic/etc/ros
- ROS_HOME
ROS默认的home路径是~/.ros,默认情况下该目录下保存log文件和test的结果文件。通过修改这个环境变量可以改变上面两个文件的保存路径。
- ROS_LOG_DIR
该变量指向ros输出的log文件保存的目录。该变量为空时,log文件默认保存在ROS_HOME指向的目录中;设置该变量后,输出的log文件保存在ROS_LOG_DIR指向的目录中,做日志工具时很有用。一般在~/.bashrc文件中设置该变量。
- ROSCONSOLE_CONFIG_FILE
默认情况下,c++接口使用的log配置文件路径为$ROS_ROOT/config/rosconsole.config, 通过设置该变量可以配置c++接口的log信息的输出级别。
- ROSCONSOLE_FORMAT
修改log输出的格式,默认情况下的输出格式 export ROSCONSOLE_FORMAT= [${severity}] [${time}]: ${message}
- ROS_BOOST_ROOT
这个不用研究。 设置搜索boost库的地址,如果没有设置,那么默认使用ROS_BINDEPS_PATH
- ROS_PARALLEL_JOBS
这个和cmake 的-j8是类似的。
export ROS_PARALLEL_JOBS='-j8 -l8'
-j flag with an argument to run up to 8 jobs in parallel, independent of system load:
export ROS_PARALLEL_JOBS=-j8
using the -l flag to set a system load-dependent limit on parallelism. Excessive parallelism in a large build can exhaust system memory.