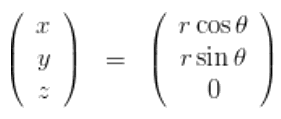add_executable(A_program src/A_program.cpp) add_dependencies(A_program B C ) # B C是package名称,不是编译结果的名称 target_link_libraries(A_program ${catkin_LIBRARIES} B_program C_program)
ros::NodeHandle n; ros::Timer timer; bool wait_for_wake = false; // 先不唤醒线程 boost::unique_lock<boost::recursive_mutex> lock(planner_mutex_); while(n.ok() ) { // check if we should run the planner (the mutex is locked) while(wait_for_wake || !runPlanner_){ //if we should not be running the planner then suspend this thread log.debug("[move_base_plan_thread] %s","Planner thread is suspending"); planner_cond_.wait(lock); wait_for_wake = false; } // 开启线程 ros::Time start_time = ros::Time::now(); //time to plan! get a copy of the goal and unlock the mutex geometry_msgs::PoseStamped temp_goal = planner_goal_; lock.unlock(); ROS_DEBUG_NAMED("move_base_plan_thread", "Planning..."); // run planner planner_plan_->clear(); bool gotPlan = n.ok() && makePlan(temp_goal, *planner_plan_); ...... }
if(gotPlan) { ROS_DEBUG_NAMED("move_base_plan_thread","Got Plan with %zu points!", planner_plan_->size()); //pointer swap the plans under mutex (the controller will pull from latest_plan_) std::vector<geometry_msgs::PoseStamped>* temp_plan = planner_plan_; lock.lock(); // 交换变量,赋值给 latest_plan_ planner_plan_ = latest_plan_; latest_plan_ = temp_plan; last_valid_plan_ = ros::Time::now(); planning_retries_ = 0; new_global_plan_ = true; //make sure we only start the controller if we still haven't reached the goal if(runPlanner_) state_ = CONTROLLING; if(planner_frequency_ <= 0) runPlanner_ = false; lock.unlock(); } // 如果没找到路径,而且还在 PLANNING 状态(机器人不动) elseif(state_==PLANNING) { ros::Time attempt_end = last_valid_plan_ + ros::Duration(planner_patience_); //check if make a plan for over time limit or maximum number of retries lock.lock(); // lock是用于这个非原子操作 planning_retries_++; // 如果参数 max_planning_retries还是默认值 -1,那转为uint32_t就是一个很大的数,就是不考虑重试次数 if(runPlanner_ && (ros::Time::now() > attempt_end || planning_retries_ > uint32_t(max_planning_retries_)) ) { // 进入 CLEARING 状态 state_ = CLEARING; runPlanner_ = false; // proper solution for issue #523 publishZeroVelocity(); // 车不准动 recovery_trigger_ = PLANNING_R; } lock.unlock(); } //if can't get new plan, robot will move with last global plan // 其实跟上面的情况一样 elseif(state_ == CONTROLLING) { movebase_log.warn("Robot in controlling, but can't get new global plan "); publishZeroVelocity(); state_ = CLEARING; recovery_trigger_ = PLANNING_R; } //take the mutex for the next iteration lock.lock(); if(planner_frequency_ > 0) { ros::Duration sleep_time = (start_time + ros::Duration(1.0/planner_frequency_)) - ros::Time::now(); if (sleep_time > ros::Duration(0.0) ) { wait_for_wake = true; // wakePlanner的函数只有一句: planner_cond_.notify_one(); timer = n.createTimer(sleep_time, &MoveBase::wakePlanner, this); } }
// set up plan triple buffer, 声明3个vector指针 // 三个plan都是global_plan,最终由controller_plan_ 传给local planner: if(!tc_->setPlan(*controller_plan_)) planner_plan_ = new std::vector<geometry_msgs::PoseStamped>(); latest_plan_ = new std::vector<geometry_msgs::PoseStamped>(); controller_plan_ = new std::vector<geometry_msgs::PoseStamped>();
第二部分
1 2 3 4 5 6 7 8 9 10 11 12 13
//建立planner线程 planner_thread_ = new boost::thread(boost::bind(&MoveBase::planThread, this));
// we'll provide a mechanism for some people to send goals as //PoseStamped messages over a topic, they won't get any useful //information back about its status, but this is useful for tools like rviz ros::NodeHandle simple_nh("move_base_simple"); goal_sub_ = simple_nh.subscribe<geometry_msgs::PoseStamped>("goal", 1, boost::bind(&MoveBase::goalCB, this, _1));
// /机器人几何尺寸有关参数 we'll assume the radius of the robot to be consistent with what's specified for the costmaps private_nh.param("local_costmap/inscribed_radius", inscribed_radius_, 0.325); private_nh.param("local_costmap/circumscribed_radius", circumscribed_radius_, 0.46); private_nh.param("clearing_radius", clearing_radius_, circumscribed_radius_); private_nh.param("conservative_reset_dist", conservative_reset_dist_, 3.0); private_nh.param("shutdown_costmaps", shutdown_costmaps_, false); private_nh.param("clearing_rotation_allowed", clearing_rotation_allowed_, true); private_nh.param("recovery_behavior_enabled", recovery_behavior_enabled_, true);
//创建planner's costmap的ROS封装类, 初始化一个指针,用于underlying map planner_costmap_ros_ = new costmap_2d::Costmap2DROS("global_costmap", tf_); planner_costmap_ros_->pause();
//初始化global planner try { // boost::shared_ptr<nav_core::BaseGlobalPlanner> planner_; // 模板类ClassLoader,实例化 BaseGlobalPlanner planner_ = bgp_loader_.createInstance(global_planner); planner_->initialize(bgp_loader_.getName(global_planner), planner_costmap_ros_); log.info("Created global_planner %s", global_planner.c_str()); } catch (const pluginlib::PluginlibException& ex) { log.fatal("Failed to create the %s planner, are you sure it is properly registered and that the containing library is built? Exception: %s", global_planner.c_str(), ex.what()); exit(1); }
//创建controller's costmap的ROS封装类, 初始化一个指针,用于underlying map controller_costmap_ros_ = new costmap_2d::Costmap2DROS("local_costmap", tf_); controller_costmap_ros_->pause();
//初始化local planner try { tc_ = blp_loader_.createInstance(local_planner); log.info("Created local_planner %s", local_planner.c_str()); tc_->initialize(blp_loader_.getName(local_planner), &tf_, controller_costmap_ros_); } catch (const pluginlib::PluginlibException& ex) { log.fatal("Failed to create the %s planner, are you sure it is properly registered and that the containing library is built? Exception: %s", local_planner.c_str(), ex.what()); exit(1); } // 开启costmap基于传感器数据的更新 planner_costmap_ros_->start(); controller_costmap_ros_->start();
//advertise a service for getting a plan make_plan_srv_ = private_nh.advertiseService("make_plan", &MoveBase::planService, this);
//advertise a service for clearing the costmaps clear_costmaps_srv_ = private_nh.advertiseService("clear_costmaps", &MoveBase::clearCostmapsService, this); // if we shutdown our costmaps when we're deactivated... we'll do that now if(shutdown_costmaps_){ log.debug("[move_base] %s","Stopping costmaps initially"); planner_costmap_ros_->stop(); controller_costmap_ros_->stop(); }
GlobalPlanner类,继承nav_core::BaseGlobalPlanner, Provides a ROS wrapper for the global_planner planner which runs a fast, interpolated navigation function on a costmap.
第四部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// 载入recovery behavior, 这部分是状态机的设计问题,优先加载用户的设置,如果没有则加载默认设置 if(!loadRecoveryBehaviors(private_nh)){ loadDefaultRecoveryBehaviors(); } //initially, we'll need to make a plan state_ = PLANNING;
//we'll start executing recovery behaviors at the beginning of our list recovery_index_ = 0;