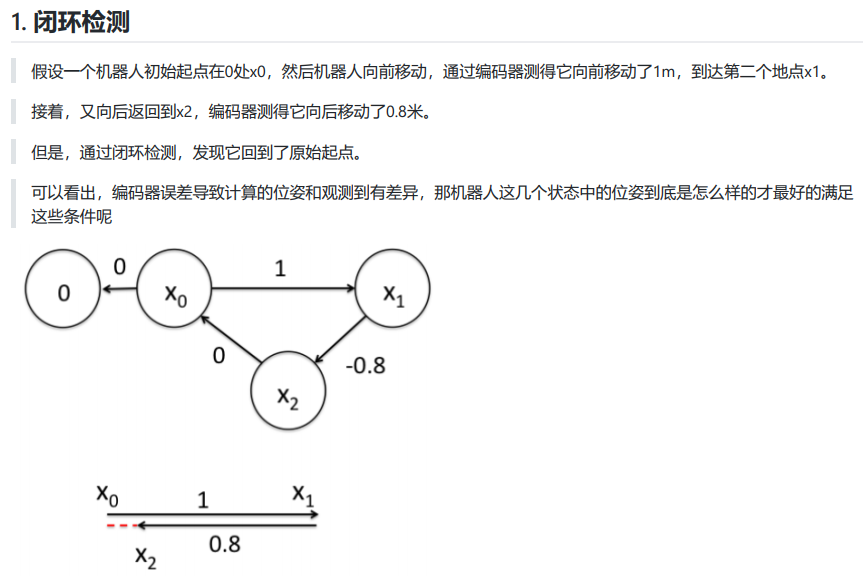
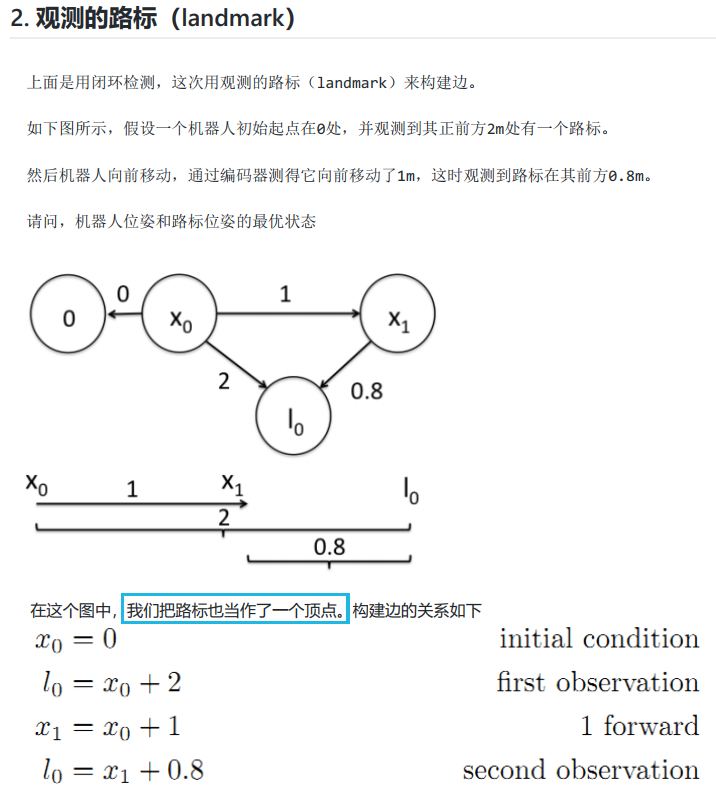
以下为ubuntu18版本的g2o对应的代码,和16版不兼容。TEB的常见安装问题就是16版到18版不兼容1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 求解器一般有两种, TEB用的是 Levenberg
typedef g2o::BlockSolver<g2o::BlockSolverTraits<3, 3>> Block; // 每个误差项优化变量维度为3,误差值维度为1
Block::LinearSolverType* linearSolver = new g2o::LinearSolverDense<Block::PoseMatrixType>();
Block* solver_ptr = new Block(std::unique_ptr<Block::LinearSolverType>(linearSolver) );
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg(std::unique_ptr<Block>(solver_ptr) );
g2o::SparseOptimizer optimizer;
// setAlgorithm()需要传递一个优化算法
optimizer.setAlgorithm(solver);
optimizer.setVerbose(true);
optimizer->initMultiThreading();
// ......
optimizer.optimize(maxIterations); //开始优化,设置迭代次数
- static bool initMultiThreading();
Eigen3.1开始,要求we call an initialize函数,如果从不同线程调用Eigen
如果g2o基于OpenMP编译,而且Eigen版本高于3.1,则这个函数调用 Eigen::initParallel
LinearSolver
它用来求解线性方程 ,可以从PCG、CSparse、Choldmod、Dense、Eigen选择求解方法。
LinearSolverCSparse:使用CSparse法。继承自LinearSolverCCS
LinearSolverCholmod :使用sparse cholesky分解法。继承自LinearSolverCCS
LinearSolverDense :使用dense cholesky分解法。继承自LinearSolver
LinearSolverEigen: 依赖项只有eigen,使用eigen中的sparse Cholesky 求解,因此编译好后可以方便的在其他地方使用,性能和CSparse差不多。继承自LinearSolver
LinearSolverPCG :使用preconditioned conjugate gradient 法,继承自LinearSolver
选哪个求解器很重要,有一次使用LinearSolverDense,结果260秒才迭代一次,换成LinearSolverCSparse,0.4秒就迭代一次
TEB是涉及到CSparse和Choldmod,默认使用前者
解析器solver的另一种创建方式
1 | // 加载几组 solver |
construct函数比上面的LinearSolverDense系列更灵活,设置求解器更精准。
使用listSolvers输出所有可用solver到文件,这个结果是和使用了多少G2O_USE_OPTIMIZATION_LIBRARY有关的,上面的5个应该涵盖了所有求解器,结果非常多。比如不加载G2O_USE_OPTIMIZATION_LIBRARY(eigen),那么lm_var不可用,会报错 SOLVER FACTORY WARNING: Unable to create solver lm_var
listSolvers会输出所有求解器名称和解释,比如1
lm_var Eigen Levenberg: Cholesky solver using Eigen's Sparse Cholesky methods (variable blocksize)
优化结果
optimizer.setVerbose(true)后才能看到优化过程
或者g2o::SparseOptimizer::chi2(),优化前后各调用一次,可得到优化前后误差变化1
2
3
4
5iteration= 0 chi2= 6973711.783675 time= 0.228985 cumTime= 0.228985 edges= 3995 schur= 0 lambda= 42.450053 levenbergIter= 1
iteration= 1 chi2= 477444.019837 time= 0.219176 cumTime= 0.448161 edges= 3995 schur= 0 lambda= 14.150018 levenbergIter= 1
......
iteration= 20 chi2= 10344.665262 time= 0.200148 cumTime= 4.63974 edges= 3995 schur= 0 lambda= 1.634041 levenbergIter= 1
iteration= 21 chi2= 10344.665262 time= 0.461369 cumTime= 5.10111 edges= 3995 schur= 0 lambda= 112290463347.367386 levenbergIter= 8time是每次的优化时间,cumTime是累计用时。可以看到chi2最后几次迭代不怎么变化了,说明iteration设置大了












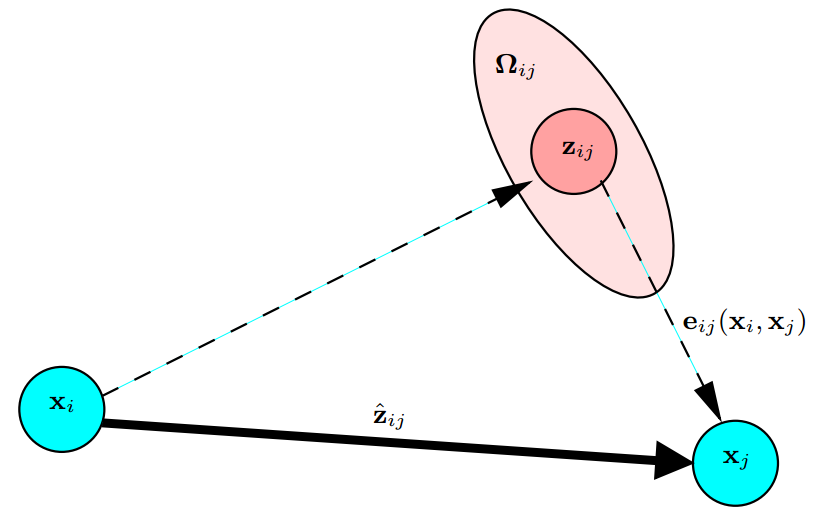



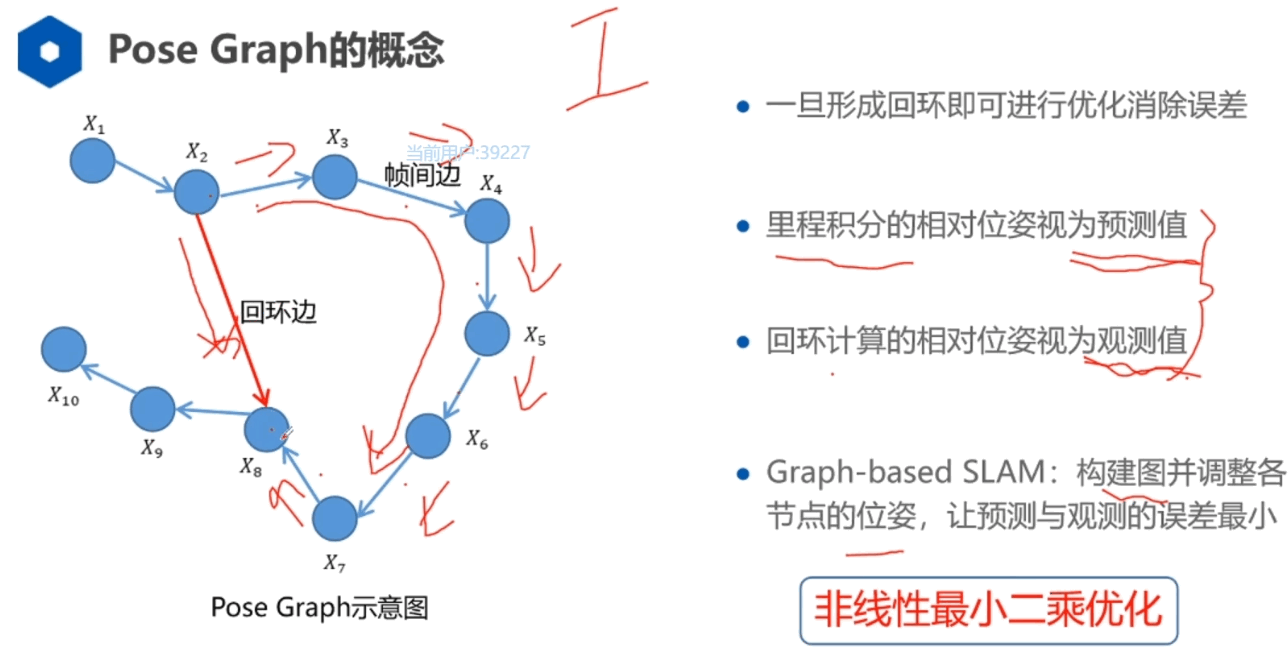
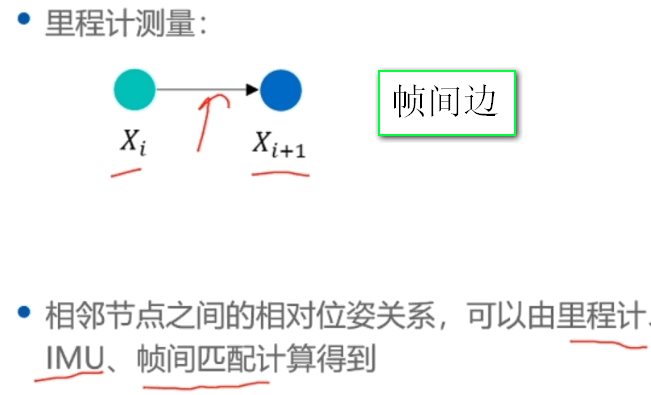
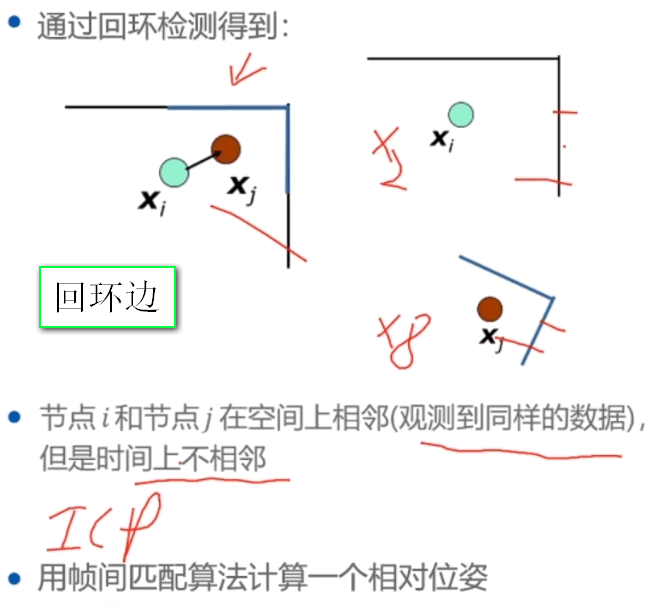
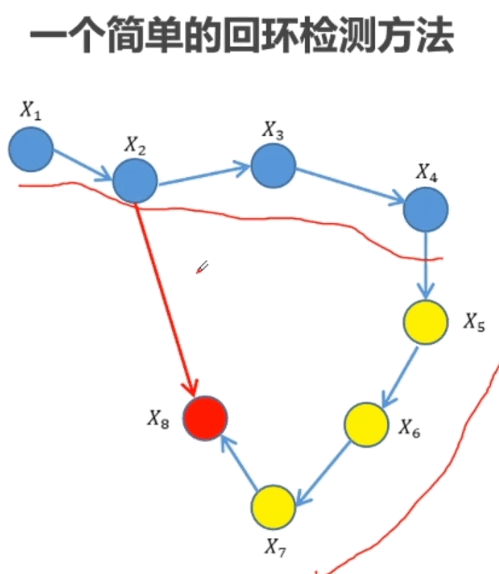



 和 J[0](1, 2)的推导过程](https://s2.loli.net/2023/03/04/8WgEX6FU4SN2wK1.png)