
接上一篇,把激光雷达的扫描数据插入子图,是通过ActiveSubmaps2D所提供的插入器对象range_data_inserter_完成的,也就是ProbabilityGridRangeDataInserter2D::Insert函数,用到了激光扫描的RayCasting模型。这里就涉及到论文的内容了
三维激光SLAM形成的点云地图不需要自己手动实现点云的数据结构, PCL中有写好的数据类型, 直接调用就行. 视觉SLAM形成的点云地图也可以用PCL来实现。
但是二维激光SLAM的栅格地图需要自己手动实现, 目前所有的二维激光SLAM的栅格地图都是SLAM作者自己写的,没有通用的数据结构,最后会转成ROS的地图数据结构。cartogrpaher,gmapping,hector皆是如此
理论基础
首先明确几个概念:
- Probability: 占据概率,下面用 p 表示
- CorrespondenceCost: 空闲概率(浮点型),对应的Value为线性映射到 [1-32767] 整型范围
- Odds:
hit_table和miss_table存储的是free概率,但设置和获取均为hit概率,为何中间多一个转换步骤,因为匹配操作时采用类似最小二乘的优化思想。
在占据栅格地图中,对于一个点,我们用 来表示它是Free状态的概率,用 来表示它是Occupied状态的概率,两者的和为1。
默认情况下,对于一个cell,无论hit或miss事件, 和 都是0.5。 scan经过cell后,观测值z会更新cell的状态,这显然是个条件概率的问题,现在要考虑的不是 了,而是观测的条件概率: 和
所以一个栅格实际为 hit 的概率和 miss 的概率,因此可以用贝叶斯公式进行求取
我们希望一个栅格中仅有一个值,因此引入 这一概念(两者的比值)来衡量cell的状态:
设置一个概率的最大最小值,防止分母出现0的情况,比如[0.1,0.9]。
初始情况下,一个cell的状态没有任何信息,。
cell原来的Odd是 ,现在就变成了 ,再使用贝叶斯公式变换得到
也就是说
其中k-1为上一时刻的 (cell第一次被scan更新),而k为经过一次观测后的 (cell再次被更新),显然仅是相差了 这个系数。由于栅格表示是否为障碍物,观测采用激光测距是否障碍,地图中点的更新状态有三种:hit、miss、free(不更新)。
其中表示的是当cell为障碍时,传感器认为是障碍的概率,这显然是传感器本身属性决定的,因此为常数。同样其他3种组合也均为常数,因此系数 是根据观测hit和miss决定的两个常数,即 和 两个常数。当传感器测到此cell为 hit 时,使用 ,反之是
论文中的栅格 hit 概率更新公式是
clamp是c++中的函数:将结果限制在[0, 1]。 odds运算是从占用概率计算odds,逆运算就是反过来。 我理解的是:先不看clamp,两边进行odds运算,公式就变成了这样
与上面的公式(3) 应该是一样的
注意: lua配置中的 hit_probability = 0.55 和 miss_probability = 0.49指的是 和
其他大部分SLAM实现地图更新采用对数加减的方式:
举例如下
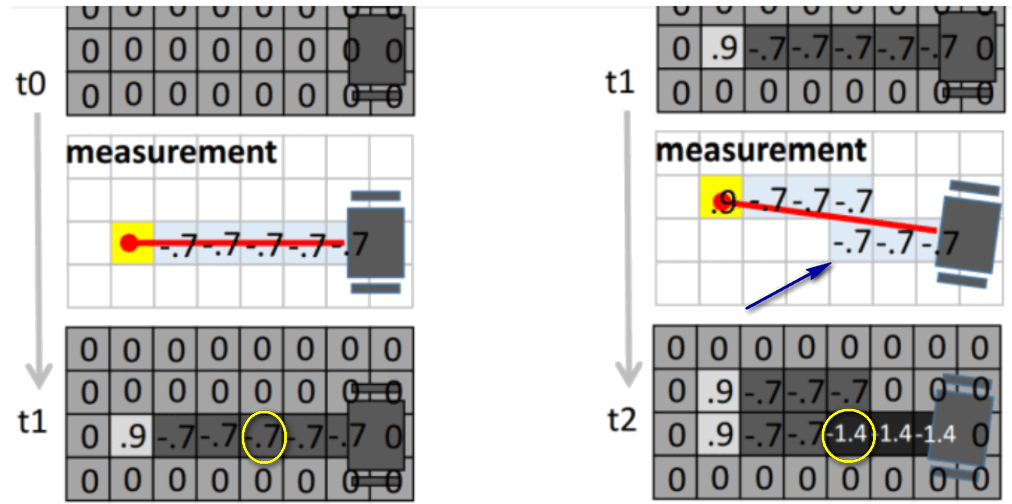
同样地,ProbabilityGrid在将点云插入到栅格地图时, 即使这个栅格被之前的点云更新过, 当前帧的点云还是会对这个栅格进行更新
第二次观测会在第一次的基础上累计,其实这里只是个举例,还不太准确,对于图中圈出的栅格,第一次是从栅格中心射过,但第二次是从角落射过, 从对角穿过对这个栅格的空闲概率的提升显然作用更大, 而只穿过一个小角落显然贡献很小,所以第二次不应该是 -0.7, 0.9的栅格也是同样道理
如果栅格地图以 odds 的形式表示,那么更新过程就只是一个乘法运算,效率也还可以。但Cartographer还是想要进一步的提高效率,它以内存空间换取时间,构建了hit表和miss表。 实际上是两个 vector<uint16>, 保存的是空闲概率映射后的索引值。 如果发生了hit事件,就从hit表中查找更新后的数据。发生了miss事件则查找miss表。
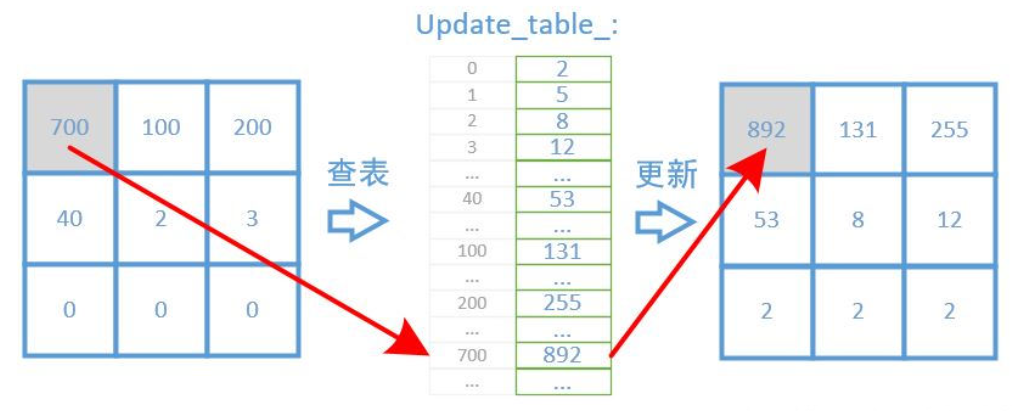
ProbabilityGrid在将点云插入到栅格地图时, 新的栅格值是预先通过查找表计算好的, 直接查表就行了, 不用再重新计算.
ProbabilityGridRangeDataInserter2D 和 两个表的构建
类ProbabilityGridRangeDataInserter2D值得关注的成员函数只有Insert,只有三个成员变量:1
2
3
4const proto::ProbabilityGridRangeDataInserterOptions2D options_;
// 用于更新栅格单元的占用概率的查找表
const std::vector<uint16> hit_table_;
const std::vector<uint16> miss_table_;
构造函数1
2
3
4
5
6
7ProbabilityGridRangeDataInserter2D::ProbabilityGridRangeDataInserter2D(
const proto::ProbabilityGridRangeDataInserterOptions2D& options)
: options_(options),
hit_table_(ComputeLookupTableToApplyCorrespondenceCostOdds(
Odds(options.hit_probability()) ) ),
miss_table_(ComputeLookupTableToApplyCorrespondenceCostOdds(
Odds(options.miss_probability()) )) {}
其中调用的名字很长的函数在probability_values.cc文件中,它完成查找表hit_table_和miss_table_的初始化。
1 | // 构建查找表, 处理某一个cell的 CorrespondenceCostValue 已知时 如何更新的情况 |
uint16的范围是[0, 65535],定义的vector有 32768 个元素,先根据参数 odds插入了一个元素,然后在for循环里又插入了剩下的32767个元素。
对第一个元素,把参数odds(lua中配置的hit和miss概率)转为空闲概率对应的[1, 32767]的索引值,然后再加上32768,结果的范围是[32768+1, 65535]。 CorrespondenceCostToValue函数极为复杂,不用研究细节了。
对剩下的元素,所有odds均乘以更新系数( 和 )并放入表格中
对于参数hit_probability=0.55, hit_table_第一个成员是47104。 对于参数miss_probability=0.49, miss_table_第一个成员是49562。 两个表大不相同。
变量kValueToCorrespondenceCost的定义:const std::vector<float>* const kValueToCorrespondenceCost =
PrecomputeValueToCorrespondenceCost().release();,其实是一系列的浮点数,查看定义会发现相应函数的参数全都写死了。我运行了一下,发现结果是0和0.1到0.9的32768个数,其中0.1到0.9之间的一大堆数,间隔大约是0.24。 其实是建立了如下的关系
代码里加上了kUpdateMarker,所以Grid2D的成员函数FinishUpdate里会将存储值都减去一个kUpdateMarker
kUpdateMarker 为已更新后的标志量,是为了防止miss和hit重复对地图更新,其值为32768,为uint16的最高位,其操作的方式是,更新时加上,更新完了后减去。
补充 ,看函数GetProbability获取占用概率1
2
3
4
5
6float ProbabilityGrid::GetProbability(const Eigen::Array2i& cell_index) const
{
if (!limits().Contains(cell_index)) return kMinProbability;
return CorrespondenceCostToProbability(ValueToCorrespondenceCost(
correspondence_cost_cells()[ToFlatIndex(cell_index)]) );
}correspondence_cost_cells就是栅格的索引值,保存的是空闲概率转成uint16后的[0, 32767]的值,0代表未知。
ValueToCorrespondenceCost是索引值转成空闲概率
参考:
查找表与占用栅格更新