
先接上篇,不是第一帧激光数据的情况,上来是scanMatch函数,也就是GridSlamProcessor::scanMatch(在文件gridslamprocessor.hxx)。
主要部分
1 | inline void GridSlamProcessor::scanMatch(const double* plainReading) |
开始的都没意思,直接看ScanMatcher::optimize,在scanmatcher.cpp里,开头又是一个重要函数score,在scanmatcher.h里。它根据地图、激光数据、位姿迭代求解一个最优的新的位姿出来。
代码比较复杂,直接看整个scan函数(包括了optimize和score)的评分算法的理论:
对于栅格地图的环境地图模型,一般采用基于似然场模型(likelihood field range finder mode)的扫描匹配算法来进行激光雷达数据与地图的匹配。 该算法通过评估当前时刻位姿的激光雷达数据中每一个激光点与该时刻栅格地图的匹配程度,并将评估得到的每个激光点得分进行累加,得到当前时刻激光雷达数据与地图匹配的总分数,得分越高说明该时刻激光雷达信息与地图匹配程度越高,即机器人位姿越精确。由于该算法能够根据机器人当前时刻状态、 观测值和地图信息直接得到该时刻位姿的匹配程度,因而该算法常与基于粒子滤波的定位算法结合使用,用于选取各粒子中得分最高的位姿,并计算得分, 从而完成机器人位姿的确定,其原理如图: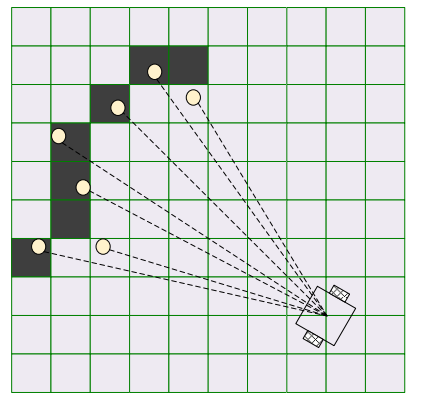
黑色的格子代表前一时刻栅格地图中障碍物的位置, 圆形的点表示以里程计运动模型作为提议分布得到的机器人位姿估计为基础,将当前时刻激光雷达数据转换到栅格地图坐标系中的激光点的分布。把激光雷达的坐标转换到世界坐标系: 先旋转到机器人坐标系,然后再转换到世界坐标系。
该位姿下观测信息与地图匹配得分的具体算法步骤如下:对于当前激光雷达数据中任意一个激光点,设其端点在世界坐标系中坐标为 lp ,则其对应栅格地图中坐标为 phit ,对 phit周围八个栅格进行障碍物判定,并计算这些障碍物的平均坐标 pavr, 求出 pavr与 phit 的距离 dist 。 该激光点的评分可由下式表示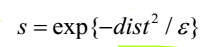
ε为基于扫描匹配概率的激光方差,对该时刻所有激光点进行上式的计算,并将评分进行求和,分数越高说明该位姿的可信度越高。 对当前时刻所有粒子位姿进行扫描匹配运算, 并根据得分实现粒子的权重更新,最后求出粒子群的平均评分sumScore/m_particles.size()
如果设置的minimumScore参数过大,一些粒子的匹配会失败,因为要求太高了,gmapping会出现下列信息:
gmapping变成使用里程计进行位姿估计,这其实是不好的,因为从论文可知激光精度比里程计精确得多,但是注意粒子的权重计算还是调用likelihoodAndScore函数。
试验小强的scan match评分
直接修改gridslamprocessor.hxx的scanMatch函数。 小强的gmapping编译有问题,执行catkin_make --pkg gmapping之后,需要 cp /home/xiaoqiang/Documents/ros/devel/lib/gmapping/slam_gmapping /home/xiaoqiang/Documents/ros/src/gmapping/launch,否则roslaunch找不到节点文件
根据测试,激光评分多数在140~160,有时也会超过160.
for循环剩下的部分
1 | /*矫正成功则更新位姿*/ |
重采样
resample函数: 该函数在gridslamprocessor.hxx。首先是备份老的粒子的轨迹,即保留叶子的节点。然后是需要重采样还是不需要重采样,如果不需要重采样,则权值不变。只为轨迹创建一个新的节点,每个粒子更新地图。当有效值小于阈值的时候需要重采样,通过resampleIndexes提取到需要删除的粒子。删除粒子后,保留当前的粒子并在保存的粒子的节点里新增一个节点。删除要删除粒子的节点,保留的粒子进行数据更新,将每个粒子的设置同一个权重。最后更新一下地图。
resampleIndexes:该函数在particlefilter.h中,使用轮盘赌算法,决定哪些粒子会保留,保留的粒子会返回下标,里面的下标可能会重复,因为有些粒子会重复采样,而另外的一些粒子会消失掉。
首先计算总的权重,计算平均权重值(interval),根据权值进行采样,target是0-1分布随机选取的一数值,当总权重大于目标权重的,记录该粒子的索引,target在加上一个interval。如果某个粒子的权重比较大的话,就被采样多次。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33// 简化声明
int resampleIndexes(const std::vector<Particle>& particles, int nparticles) const
{
Numeric cweight=0;
/*计算总的权重*/
unsigned int n=0;
for (typename std::vector<Particle>::const_iterator it=particles.begin(); it!=particles.end(); ++it)
{
cweight+=(Numeric)*it;
n++;
}
if (nparticles>0)
n=nparticles;
//compute the interval
Numeric interval=cweight/n;
// drand48 返回服从均匀分布的·[0.0, 1.0) 之间的double随机数
Numeric target=interval*::drand48();
// 如果某个粒子的区间为4*interval。那么它至少被采样3次。
cweight=0; n=0;
std::vector<unsigned int> indexes(n);
unsigned int i=0;
for (typename std::vector<Particle>::const_iterator it=particles.begin(); it!=particles.end(); ++it, ++i)
{
cweight+=(Numeric)* it;
while(cweight>target)
{
indexes[n++]=i;
target+=interval;
}
}
return indexes;
}